
The narrative in AI infrastructure over the last two years has been dominated by the enormous and growing demand for compute capacity and its economic consequences, such as the buildout of data centers and the consequent shortages of key resources such as land, water, power, and copper.
But of all these bottlenecks, memory is by far the most significant. The demand for memory is now outpacing the demand for other drivers of compute capacity. The implications of this will ripple through not just the economics of data centers, but the cost of every single consumer and enterprise hardware device.
In this piece, we unpack the market action around memory prices, its ripple effects across the consumer and industrial electronics market, and the supply and demand curve that is emerging around AI. Critically, we explain why the amount of memory being purchased by AI companies like OpenAI seems to be more than what they need, and how the threat of on-device inference might actually be incentivizing an engineered memory shortage.
Memory Prices in 2025 & 2026
The price of memory has been incredibly volatile in the last two years. Memory market disruption began in the summer of 2025 with volatile tariff policies. During this period, companies minimized the risk of unexpected pass-through costs by reducing safety stock orders, lowering demand relative to earlier in the year.
At the same time, the secondary memory market stagnated. Typically, global memory production capacity expands when major producers, such as Samsung, upgrade their lines and sell legacy equipment to budget manufacturers. This cycle effectively halted when Korean firms, fearing US retaliation for selling technology to China-adjacent entities, chose to warehouse functional machinery rather than resell it, leaving valuable production capacity idle. This slowdown was exacerbated by the US Commerce Department imposing strict licensing requirements to import US equipment on semiconductor giants like Samsung and SK Hynix.
The price increases in memory began in fall 2025 when hyperscalers and frontier AI giants began formalizing plans and budgets for data center capital expenditures in 2026 and beyond. These price increases began with ostensibly one-off 10% hikes from makers of data storage hardware, TSMC and Sandisk, in early September 2025, which were followed in the next two weeks by a 30% price increase from Micron, a primary manufacturer of DRAM and NAND memory chips.
In October 2025, it was reported that OpenAI alone planned to consume up to 40% of global DRAM availability, or 900K wafers per month, for its global Stargate compute cluster. This memory capacity would be supplied via two deals signed simultaneously with Samsung and SK Hynix. As part of this deal, Samsung would work with OpenAI on the operation and architecture of the Stargate data center in South Korea. These deals were both to buy uncut, unfinished raw wafers, not completed memory modules, leaving flexibility for the creation of RAM variants or HBM memory stacks (though Samsung and SK Hynix will likely be the companies making these components). South Korean presidential adviser, Kim Yong-beom, said in October 2025 that OpenAI was “seeking to order 900,000 semiconductor wafers in 2029,” but did not clarify how many the company would be purchasing per month in the period between 2025 and 2029. The production of 900K wafers per month would not likely be achieved until closer to 2029, as Samsung and SK Hynix were estimated to have around 680K and 620K wafers per month capacity, respectively, as of February 2026. Claims that OpenAI will be consuming 40% of global memory output are based on future capacity projections.
This announcement further increased prices for memory hardware components of all types, given the degree of interchangeability of memory infrastructure components with differing speed and permanence characteristics. In the following months, memory price growth further accelerated with contracting supply: In early December 2025, DRAM inventory levels were down 80% versus the same time in 2024, falling to only three weeks of available supply at then-current consumption rates (down from 9.5 weeks of supply in July 2025).
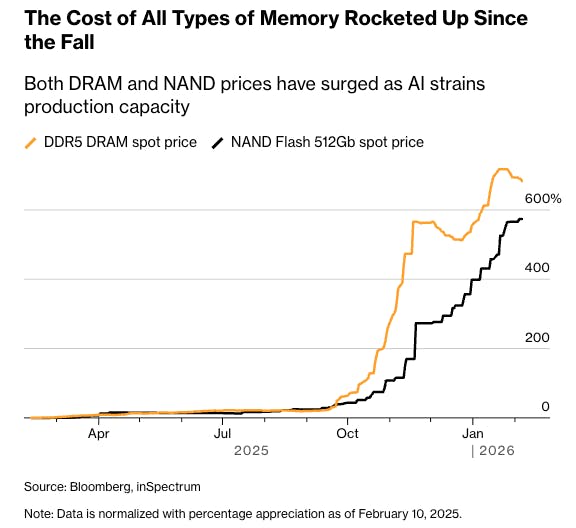
Source: Bloomberg
As of February 2026, prices have risen over 500% for NAND chips and over 600% for DRAM chips. The impacts of this sudden increase in prices are wide-reaching, but their drivers may be even more important. Will lower memory availability to consumers increase reliance on cloud-based storage and demand for data centers? Is the window of opportunity for on-device AI closing as soon as it has opened?
Memory Storage Types
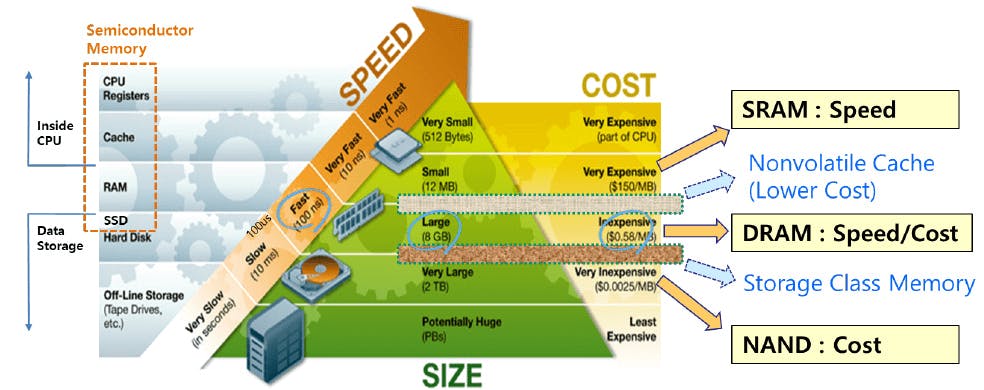
Computer memory, like neurological memory, is the infrastructure that enables long-term and short-term recall and storage of information. Memory storage hierarchy allows a computer to balance speed, capacity, and cost by arranging different technologies in tiers based on their proximity to the processor.
At the very top of this hierarchy is SRAM (Static Random Access Memory), a volatile and ultra-fast medium integrated directly into CPU caches to store actively in-use information with sub-nanosecond latency. Below this sits DRAM (Dynamic Random Access Memory), which serves as the system's main "working memory"; it provides higher capacity for open applications and active data but operates with slightly higher latency (tens of nanoseconds) and requires constant power to refresh its data. Finally, the long-term storage tier relies on NAND Flash, a non-volatile technology found in Solid State Drives (SSDs) that retains vast amounts of data without power, trading the speed of upper-tier latency (operating in microseconds rather than nanoseconds) for higher-volume persistent archival capabilities.
Source: Nomad Semi
NAND
NAND flash is a non-volatile storage technology, meaning it retains data without requiring power, unlike DRAM or SRAM, which lose their contents the moment power is removed. NAND flash memory is found in SSDs, USB flash drives, SD cards, and smartphones. The name "NAND" derives from the Boolean logic gate of the same name (NOT AND), which describes how the storage cells are electrically configured and how they represent binary data.
Though it isn’t part of the OpenAI deal, NAND has been impacted by the memory shortage as allocation has been diverted towards more dynamic memory components. For example, Samsung announced in November 2025 that it would be reallocating NAND production to DRAM across Korean fabrication facilities.
DRAM
DRAM, or Dynamic Random Access Memory, is the primary working memory in virtually all modern computing devices. Unlike non-volatile storage such as NAND flash, DRAM is volatile, meaning it loses its entire contents the moment power is removed. For non-AI server systems, DRAM already comprises nearly 50% of hardware costs. Both within compute clusters and consumer electronics, there are several main types of DRAM in use as of February 2026, which have all increased in price in recent months:
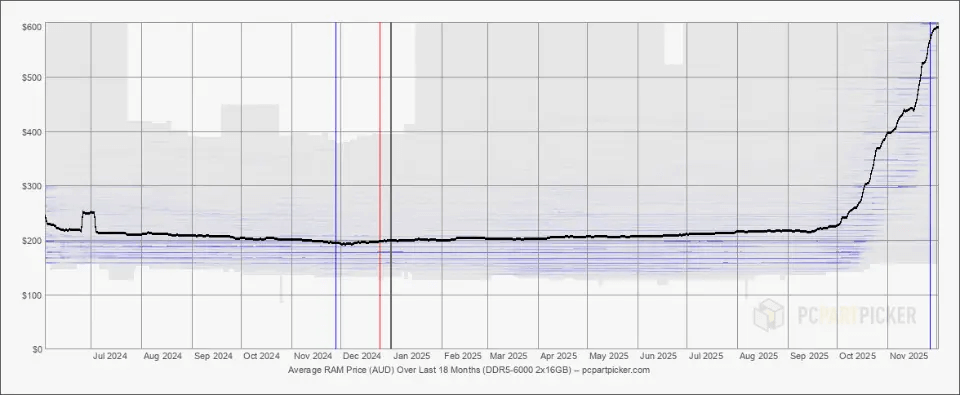
DDR5 (Double Data Rate gen 5) is the standard memory used in desktop and laptop computers, designed to balance performance, capacity, and cost for general computing tasks. It comes in removable DIMM modules, making it the only one of the three that users can upgrade after purchase.
DDR5 spot prices have risen 600% in the last six months. As of December 2025, 64GB DDR5 wafer kits cost more than the gaming consoles they are used for. 32GB DDR5 kits more than doubled in value between July 2025 and the end of the year. In November 2025, Samsungs topped pricing DDR5 DRAM altogether, given its inability to commit to meeting future demand beyond existing contracts.
Source: AV Tech
LPDDR5X (Low Power DDR5 with X meaning “Enhanced”) is a low-power variant built for smartphones, tablets, and thin laptops, where battery life matters more than peak performance. It's soldered directly to the device's board at the cost of upgradeability, but the benefit of a smaller, more power-efficient design.
GDDR6 (Graphics Double Data Rate 6) is purpose-built for discrete graphics cards, where feeding thousands of GPU cores requires enormous memory bandwidth above all other concerns. It achieves this through PAM4 signaling, a more advanced electrical technique that allows it to move far more data per second than either DDR5 or LPDDR5X, at the cost of higher power consumption and heat.
High Bandwidth Memory (HBM)
High Bandwidth Memory (HBM) is a high-performance memory architecture designed for applications that need to move enormous amounts of data very quickly, such as GPU rendering and AI workloads. Instead of placing memory chips on a circuit board at some distance from the processor, HBM stacks multiple DRAM dies on top of one another and connects them using tiny vertical electrical channels drilled through the silicon itself, called Through-Silicon Vias (TSVs). These stacks are then mounted directly alongside the processor on a shared silicon base called an interposer, keeping the two components in extreme proximity. This tight integration, combined with an exceptionally wide data bus that allows far more data to travel in parallel compared to conventional graphics memory, gives HBM significantly higher bandwidth and better power efficiency per bit transferred than traditional planar memory solutions like GDDR6.
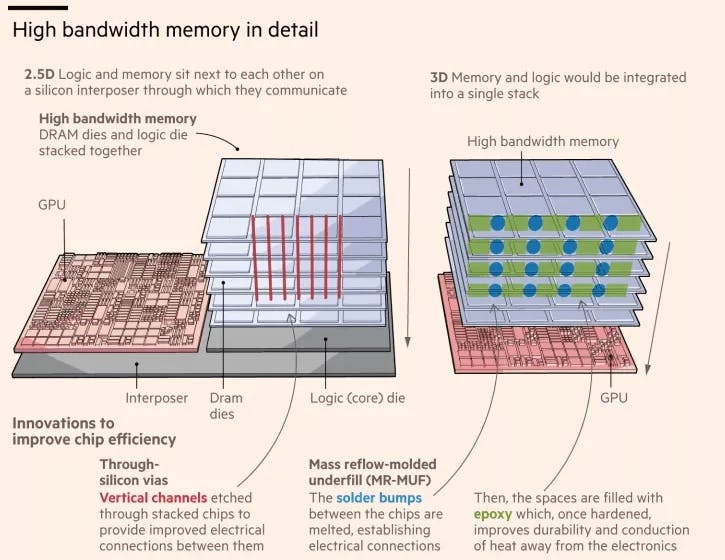
Source: Financial Times
It is not the raw logic computation that consumes the most energy in AI chips, but rather the continuous movement of data between the GPU and memory. HBM addresses this by sitting physically closer to the processor and offering a high-bandwidth connection to data, cutting the energy cost of each data transfer compared to conventional DDR. HBM delivers data transfer rates an order of magnitude faster than DDR and is purpose-built for the demands of large-scale parallel processing, making it a fit for GPUs.
Memory Prices Through History
Historically, supply and demand for memory chips have evolved cyclically, with improvements driven by two principles:
Moore’s Law: the observation that the number of transistors on a microchip doubles approximately every two years, leading to exponential increases in computing power and performance, while reducing costs
Dennard Scaling: as transistors shrink, their power density remains constant, allowing power usage to stay in proportion to area, while voltage and current scale downward with size
The combination of these dynamics resulted in more transistors per chip in parallel with more efficient computing clusters, creating lower cost-per-bit prices and resulting in a race-to-the-bottom for memory providers and a boom in memory capabilities for customers. This progressive improvement slowed down in the last decade, falling behind improvements in other layers of the compute stack. While the death of Moore’s law has been well-documented in logic chips, the slowdown has been even more dramatic for memory chips.
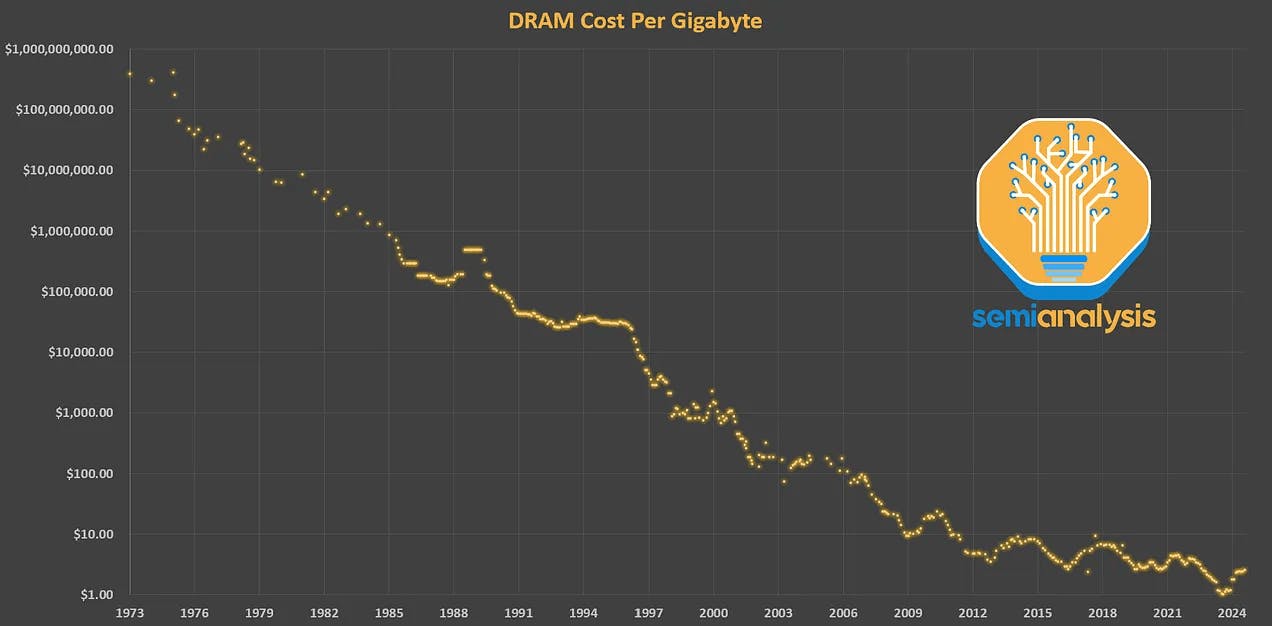
Source: SemiAnalysis
The drivers of cyclicality for memory are similar to other commodity hardware elements, which rise and fall in price in line with changing demand and stockpiling at favorable prices along with the time and investment required for new supply to come online.
Memory Prices Today
As we outlined above, the primary driver of memory price increases is demand from hyperscalers and AI labs, which are buying up existing DRAM wafer capacity to fuel ongoing data center growth. Ostensibly, these companies are consuming memory supply to enable training and inference of more advanced AI capabilities, including making progress in tasks that are currently limited by available model context (memory in AI systems is used for both storage of model weights and storage of session context, and critically for RL training). At CES in January 2026, Jensen Huang referenced this roadblock in discussing AI infrastructure, saying, “an HBM is no longer large enough,” while presenting a slide that said, “Context is the new bottleneck.” These players have reportedly already begun negotiating DRAM supply contracts for 2027.
At the same time, the chipmakers responding to this demand influx are reallocating capacity from NAND to DRAM production, impacting memory at all levels. Samsung announced in November 2025 that it would be reallocating NAND production to DRAM across Korean fabrication facilities despite rising prices and demand in both markets. Other companies, like ASUS, which have traditionally been OEM consumer electronics makers, have reportedly considered entering the DRAM market to address memory shortages. Similarly, Micron announced in December 2025 that it plans to wind down its Crucial line of memory products for consumer devices to prioritize AI memory assets, saying, “The AI‑driven growth in the data center has led to a surge in demand for memory and storage. Micron has made the difficult decision to exit the Crucial consumer business to improve supply and support for our larger, strategic customers in faster‑growing segments.”
One memory industry consultant described the dynamic for memory producers, and the pull for investors in saying:
“It’s literally free money… They’re not doing anything different. No new factories, no new shipping, no new nothing. All they do is just get twice as much money as they were getting a year ago.”
Stocks of both producers and consumers of memory components have been repriced accordingly. Since September 2025, consumer tech hardware stocks have fallen around -10% on concerns about margins and production levels, while memory chip stocks have risen +160%. Korea’s SK Hynix Inc. is up over 150%, Japan’s Kioxia Holdings Corp. and Taiwan’s Nanya Technology Corp. are each up over 270% each in that span, and American Sandisk Corp. has risen nearly 1000%. Sandisk’s price explosion in particular was a surprise even to those in the memory industry, as it became the top-performing S&P-500 stock in 2025.
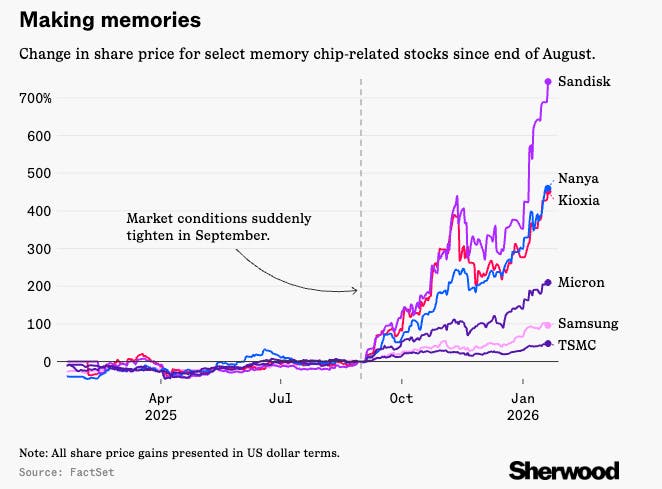
Source: Sherwood
In Sandisk’s August earnings call, the company’s CFO said, “We’re getting much tighter and to a point where sometimes our customers want products we don’t have.” Only a month later, in September, he updated this guidance as, “The market is tight, and we’ll continue to see opportunities to increase prices across the board.”
How Long Will the Shortage Last?
While memory chip consumer stocks are pricing in normalization of supply within one or two quarters, chipmakers like SK Hynix have said the shortage is likely to persist until 2028, with orders booked fully through Q4 2027. The company announced the expansion of its under-construction $500 billion fabrication facility, which is expected to come online in February 2027.
This prolonged limited supply of memory chips has also impacted international export agreements. In January 2026, the US Commerce Department issued a rule limiting H200 AI processor sales to Chinese companies, partially on the basis of memory supply limitations. One US representative wrote in a letter to Commerce Secretary Howard Lutnick: “Due to severe supply constraints, chips equipped with HMB3E bound for China represent an opportunity cost when it comes to HMB3E that could otherwise be utilized by American customers,” and said that the shortage of DRAM chips posed an “immediate challenge” to existing export and licensing agreements. These export agreements allow companies to make sales to China only if those orders won’t cause delays for US buyers or re-allocate foundry capacity away from that which could fill US orders.
Is OpenAI Overbuying Memory?
Even considering the scale of the AI-motivated data center buildout, the extreme impact on memory wafer pricing warrants closer consideration. When you look at how much memory OpenAI is actually purchasing relative to how much it demonstrably needs for its stated infrastructure goals, you start to see a significant discrepancy.
The math, while pretty involved, may tell a straightforward story (if you’re interested in the details of our analysis, see the Appendix). OpenAI has contracted 900K memory wafers per month from Samsung and SK Hynix. Partner commentary seems to indicate that’s a monthly number, so that represents 10.8 million wafers over 12 months. In terms of demand, a fully built-out 10GW Stargate cluster would require ~3 million GB200 Bianca Boards. Each board requires ~50% of a memory wafer in total; split between the HBM3e stacks embedded into its two B200 GPU (~30%) and its 480 GB of LPDDR5X system memory (~20%). That puts total wafer demand for the entire cluster at ~3 million wafers.
Therefore, according to our best estimates, OpenAI likely needs less than 30% of the 10.8 million wafers it's planning to buy. That’s a sizable shortfall; so what’s the explanation? The most straightforward reading is aggressive forward positioning against future capacity needs. But a sharper interpretation might be that OpenAI, and potentially other AI labs making similar purchases as part of their 2026 CapEx plans, are deliberately cornering memory supply to preclude the possibility of on-device inference becoming a widespread alternative.
The Threat of On-Device Compute
Entertain the hypothetical. Let’s say OpenAI is buying up more memory than necessary in order to prevent users from having compute alternatives, like sufficient on-device memory to run models locally. While OpenAI is the main lab with disclosed memory-specific deals announced, it is possible that other AI labs or compute providers are planning similar purchases as part of their 2026 CapEx plans. Despite the potential benefits for AI labs of releasing smaller versions of models that can run on-device, alleviating demand for cloud compute and reducing latency demands for inference on the cloud, the risk of a runaway train away from the cloud altogether is too high.
As of 2025, open-weight models available for download and fine-tuning lagged state of the art models by only three months, and the performance of frontier AI labs was replicable on consumer devices only 12 months after launch. This makes the possibility of consumers running models for free, at the one-time cost of memory acquisition, very real.
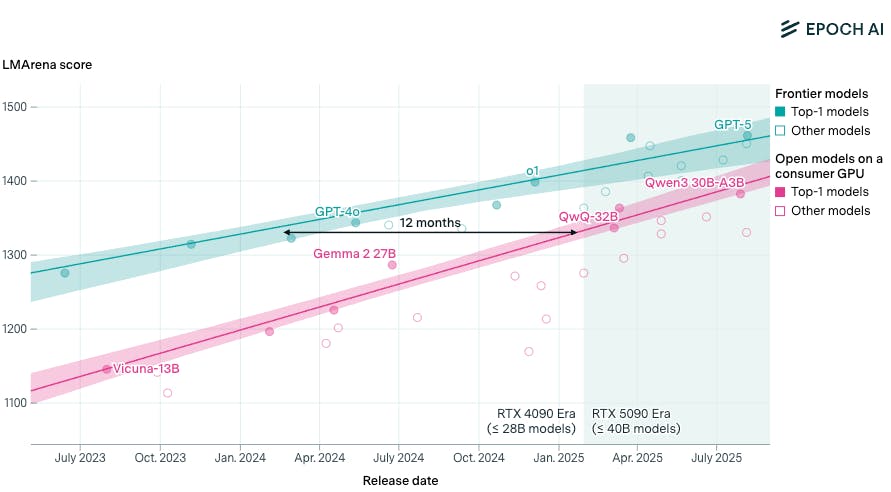
Source: Epoch AI
How big of a deal would the loss of inference be for proprietary model providers? These companies have a business model that (outside of ads) centers around charging customers for inference, as opposed to access to model weights (the outputs of model training). AI companies today are setting up infrastructure that will theoretically serve model training and inference in equal parts. It is worth distinguishing that model training costs are incurred before revenue from that model, while inference charges are earned as access to the model is distributed. In one study, researchers found that the cost of inference compute scales with the square root of training compute, but that total inference costs across queries result in costs that roughly equal those of training the models. The report notes anecdotally that:
“In February 2024, Sam Altman claimed that OpenAI currently generates around 100 billion tokens per day, or about 36 trillion tokens per year. Given that modern language models are trained on the order of 10 trillion tokens and tokens seen during training are around three times more expensive compared to tokens seen or generated during inference, a naive analysis suggests OpenAI’s annual inference costs are on the same order as their annual model training costs.”
This means the loss of inference demand could leave AI companies holding that bag for half of the total compute capacity they are anticipating, and force those companies to evolve both the complexities of their AI models and the fundamental shape of their business models. Perplexity CEO Aravind Srinivas has called on-device inference the biggest threat to data centers, saying:
“If the intelligence can be packed locally, on a chip that’s running on the device, then there’s no need to inference all of it on one centralized data center, and even better, the models that are coming along with the chip are things that adapt to you… but imagine we crack something like test time training, where there are some tasks that you repeatedly do on your local system and the AI watches it and you’re fine with the AI watching it because the AI is living on your computer, its not going to the servers, and it adapts to you and over time it starts automating a lot of the things you do... that's your intelligence, you own it, it's your brain.”
Requirements for On-Device Inference
The abilities of language models that can be run on consumer devices are improving in tandem with frontier models. Those that are 12 months behind frontier models as of February 2026 still require non-negligible memory. Even the fewest-parameter LLMs require around 14GB of 16-bit memory. iPhones have historically housed between 3 and 12 GB of RAM, and laptops between 8 and 16 GB, up to 64GB in the most powerful machines. It has been estimated that 3-4 billion parameters may be the max model size that can be run locally on consumer devices, compared to state of the art models that are built with hundreds of billions to even trillions of parameters.
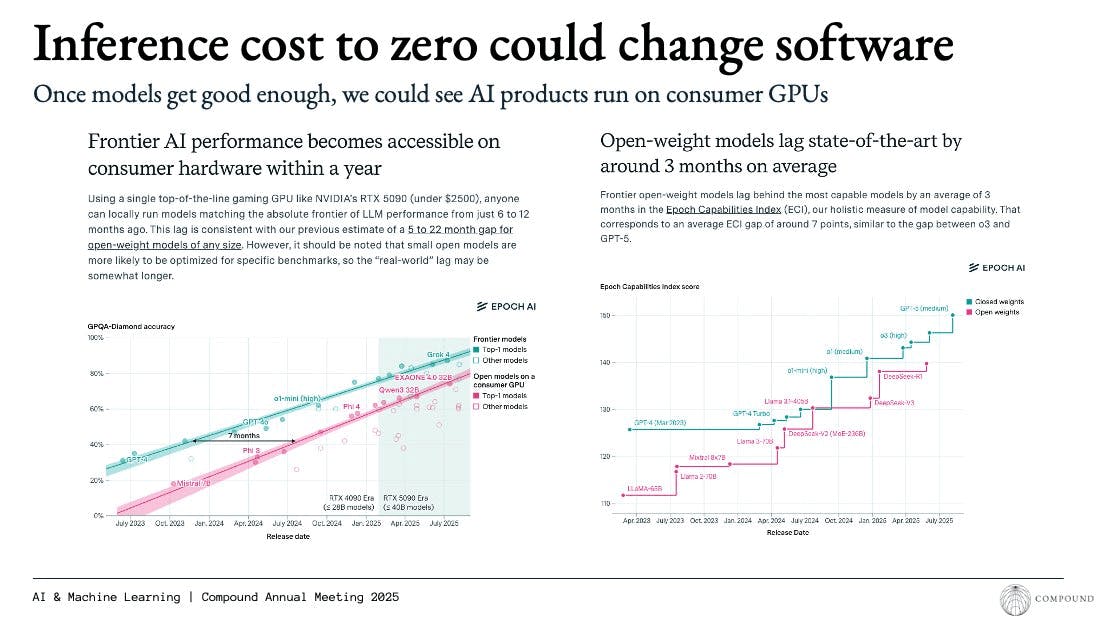
Source: Compound
Reducing memory capacity requirements is possible via techniques like transfer learning, sparsification, and quantization, but these changes can impact model accuracy and are not trivial to implement:
Quantization: By reducing precision to FP8 (8-bit) or int4 (4-bit signed), the number of bits per parameter decreases, allowing devices to run models with 2-4x more parameters. While this causes a slight loss in precision, the performance gains from running a larger model generally outweigh the downsides. Although an FP4 (4-bit) format would be ideal, it is unlikely to be supported by current client-side hardware in the near future.
Sparsification: Google DeepMind explored size reduction in fully trained models that contain a subset of parameters with zero weights. Currently, these zeros consume valuable memory bandwidth and compute cycles despite mathematically resulting in zero. Optimizing systems to avoid streaming or computing these weights represents a significant efficiency opportunity.
Pruning: The intentional creation of sparsity in models. Google’s "Sparse is Enough" research demonstrates that forcing weights to zero can maintain model quality while significantly increasing speed. Advanced techniques, such as decaying sparsity masks, have achieved model size reductions of over 50%. Furthermore, SparseGPT showed that combining pruning with quantization could reduce a 175B GPT-3 model’s memory footprint by 75% with only a 1% accuracy loss.
By combining such techniques, i.e., 4-bit quantization with 50% sparsity, publishers could achieve an 8x increase in model capacity. If these techniques can minimize accuracy loss across various use cases, modern hardware capability could improve meaningfully: iPhones could host ~5 billion parameter models, and 2025 top-end smartphones with high-speed LPDDR5x memory could run models as large as ~14 billion parameters.
There are meaningful potential benefits to being able to run inference on-device, with zero latency, connectivity, or per-query charges. AI PCs equipped with dedicated Neural Processing Units (NPUs) already exist, and support tasks like voice-activated assistants, real-time transcription, background removal in video calls, and intelligent document summarization without sending data to external servers. Intel's Core Ultra Series 3 platform, featuring an NPU rated at 50 TOPS (Trillion Operations Per Second), is expected to power over 200 laptop designs from OEMs, bringing on-device AI capabilities from premium devices into the mainstream market. The Mac Mini M4 has seen demand from AI developers using it as an always-on hardware platform for running autonomous agents locally, with its unified memory architecture allowing it to function as a low-power personal AI server. Beyond consumer computing, on-device inference is used in IoT systems like home security cameras that perform object detection and person recognition without cloud uploads, and in automobiles where driver monitoring systems, lane-keeping assistance, and navigation operate in areas without cellular service.
OpenAI's Whisper speech recognition model has become a reference implementation for on-device transcription and translation. Whisper Large-v3 achieved Word Error Rates as low as 2.7% on clean audio and processes at 216x real-time speed, allowing a 60-minute audio file to be transcribed in approximately 17 seconds, and supports 99 languages with no requirement for internet connectivity or cloud processing. Hand-tracking and eye-tracking for AR and VR headsets also rely on on-device models that process sensor data at frame rates exceeding 60Hz with latencies under 20 milliseconds, requirements that cannot be met with cloud-based inference due to round-trip network delays. Wearables and biometric monitoring systems similarly would depend on local processing to analyze heart rate variability, detect falls, monitor sleep stages, and trigger alerts in real-time without the latency, privacy risks, or connectivity dependencies inherent in cloud-based approaches.
Protecting Investment in the Cloud
Beyond defense against on-device inference, some have posited that memory supply for consumer devices is being intentionally restricted as a forcing mechanism for cloud usership. This outcome assumes a world where AI inference demand is lower than forecasted, either because users are employing on-device inference or because general usage of AI falls short of expectations. In this world, hyperscalers and AI labs, along with their financial and infrastructure partners, will have built far more cloud compute than there exists demand for.
In this world, limited on-device memory would force users to store messages, emails, photos, and personal artifacts in the cloud, instead of on their devices. This has been described as a backup plan to manufacture demand for otherwise excess data center capacity:
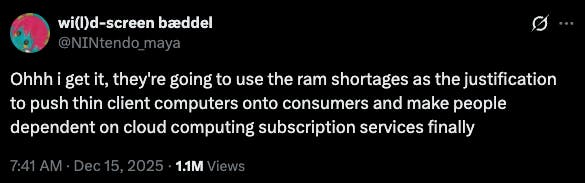
Source: X
The cloud storage market is expected to grow from $134.5 billion in 2024 to $1.1 trillion by 2035, representing nearly a 10x increase. The transition from “thick” to “thin” compute options has been justified by users and providers alike as allowing customers to share the cost of compute and memory, at the cost of higher latency and subscription-based pricing, but with the added benefit of physically lighter and smaller devices.
The Ripple Effects of the Memory Shortage
Memory components are crucial because even the most powerful processors are only as fast as the data they can access. Memory capacity and bandwidth enable a GPU to hold an entire AI model's parameters during inference, a graphics card to render high-resolution scenes on demand, a supercomputer to simulate complex physical systems at scale, and a smartphone to run multiple applications without freezing up. As memory supply remains constrained, the impacts are expected on prices and production in a wide range of industries.
Electric & Traditional Vehicles
Analysts of automotive OEMs have warned that disruption risk for traditional automakers "could start in Q2 2026," with modeled scenarios suggesting an EBIT hit of 5% for generic OEMs in 2026. Honda flagged supply risks around memory components on its Q1 earnings call, and was reportedly forced to adjust its production schedule in January 2026 in response to tightening availability. Supply pressure in this industry has been exacerbated by chip makers phasing out older DRAM generations still widely used by the automotive sector, including DDR4 and LPDDR4, which are found in advanced driver assistance systems, engine control units, and infotainment systems.
Electric vehicle makers are facing even greater pressure, given that EVs carry more memory per vehicle than traditional cars due to their software-defined architectures, ADAS capabilities, and centralized compute systems. BYD and Tesla rank among the top consumers of automotive DRAM, and the entire auto sector accounts for around 10% of the global DRAM market. Some EV makers, including BYD, are responding by attempting to reduce dependence on external suppliers through self-developing AI chips or building their own semiconductor production lines.
Mobile Phones
Rising DRAM and NAND costs inflate bill-of-materials (BoM) costs for mobile phones. That memory typically accounts for 15-20% of a smartphone's total BoM, leading to industry skepticism that production and pricing can maintain 2025 levels through the next several years. One 2026 global smartphone shipment forecasted down by 2.6%, now projecting a 2.1% decline in shipments, with low-end devices seeing BoM cost increases of around 25% versus approximately 10% for high-end phones. Those that are sold will come with lower memory on-device; Base models that have historically been sold at 8GB will likely decrease to only 4GB of RAM. Long-term DRAM contract prices, which are used by mobile phone OEMs, grew more than 75% year-over-year in Q4 2025.
This has resulted in declining share prices for phonemakers like Xiaomi, which has expressed concerns about rising input costs: a leaked budget document from Xiaomi showed that the company expected at least 25% price increases for DRAM components for each phone, despite the company's relationships with memory providers. Qualcomm told investors that phone production would be limited by memory availability, saying in its Q1 results report in February 2026 that several Chinese OEM customers had taken steps “to reduce their handset build plans and channel inventory” given the “industry-wide memory shortage and price increases,” which “are likely to define the overall scale of the handset industry through the fiscal year.”
Personal Computers
Given spot memory prices and the stockpiles of memory that some manufacturers have built up, it is considered cheaper to buy a pre-built PC than build one from scratch for the first time ever. Still, some consumer PCs are now $800-$1.5K more expensive than they were in October 2025, and PCs released in 2026 and 2027 are expected to have lower base memory availability at the same prices. The prices of external hard drives and solid state drives are both increasing as well, leaving few options for consumers looking to upgrade memory capacity off-device but still on-premise. NAND wafers make up the majority of solid- state drives (SSDs) BoMs, leading to SSD prices increasing by over 240%.
Lenovo and Dell, major PC manufacturers, have both seen their stock prices decline over 25% since the announcement of major memory component supply constraints in October, and companies like Dell, Acer, and Compal have been downgraded by analysts. Shares of makers of laptop peripherals like Logitech have also declined. In February 2026, Lenovo’s CEO described the situation in saying, “This structural imbalance between supply and demand is not simply a short-term fluctuation.”
Gaming Consoles
The impact of the memory shortage on gaming consoles and devices, and on the software providers of games that require those devices, was articulated by Tim Sweeney of Epic Games in November 2025, who said, “RAM price increases will be a real problem for high-end gaming for several years. Factories are diverting leading-edge DRAM capacity to meet AI needs, where data centers are bidding far higher than consumer device makers”. Major console maker Nintendo flagged that memory availability constraints would pressure its margins in 2026, a significant concern for a company whose Switch 2 launch depends on stable and affordable component supply.
The shortage is purportedly affecting Microsoft's Xbox more acutely than Sony's PlayStation, with Xbox reportedly carrying significantly lower inventory levels, a difference that could shape how major console OEMs weather the period of limited supply. Sony is reportedly considering pushing back the release of the next PlayStation console to 2028 or 2029 due to memory shortages.
Other Semiconductor Packages
The semiconductor and discrete GPU market is another area where the memory shortage is disrupting product strategy. AMD's Radeon line of chips, for example, is exposed because AMD does not bundle GDDR memory into its board of materials kits supplied to add-in board (AIB) partners the way Nvidia does. This means that AIB partners sourcing Radeon GPUs must secure their own GDDR allocations independently at now untenable spot market prices. The RX 9070 GRE 16GB variant, which had been anticipated as a competitive high-capacity Radeon offering, appears to have been cancelled as a result.
NVIDIA's model of maintaining centralized memory inventories for its manufacturing partners provides some structural buffer against near-term memory market volatility. Some high-capacity GPU configurations, however, like a hypothetical 24GB RTX 5080 SUPER, remain on hold indefinitely as a result of low inventories. NVIDIA has communicated to partners that a SUPER refresh may arrive in Q3 2026, though this is largely being treated as a placeholder tied to when new GDDR capacity is expected to come online rather than a firm commitment.
Two Worlds of Compute
The memory shortage is far from just another data center bottleneck. This isn’t a temporary hiccup that gets resolved as new fabs come online. This is the first visible consequence of a structural realignment of who compute infrastructure is built for. Hyperscalers and frontier AI labs have inserted themselves at the top of the memory funnel. But that has left everyone else, from automakers to smartphone OEMs and PC manufacturers, to come to the realization that their access to a critical input is no longer guaranteed.
Our analysis of OpenAI’s wafer appetite demonstrates a clear over-buy relative to its stated infrastructure requirements. Whether that reflects simple aggressive forward positioning or a deliberate cornering of the supply in order to cut off on-device competition, the effect on the rest of the market is the same. Memory that was once a critical input for entire industries is being captured upstream, and the price shock is going to reverberate across categories simultaneously.
More specifically, the underlying manufacturers of this critical resource have made it clear that this represents a durable shift rather than a temporary setback. Obviously, companies like SK Hynix, Samsung, and Micron have every incentive to bring more capacity online. But despite their intentions to invest in expanding production, they still expect these shortages to extend past 2027. And the structural demand from AI labs will only increase as capabilities improve and drive a corresponding increase in memory requirements.
The debate between cloud-dominated inference vs. on-device compute is a genuinely open one today; there’s no obvious answer. The vision of locally-run personalized AI is certainly plausible and economically appealing, but it requires memory that is currently being cornered by players who are dead-set on owning cloud-based inference (from the AI models to the supportive hyperscalers themselves, like Microsoft or Amazon). That tension will push towards one of two worlds. On the one hand, a world of cheap, abundant, on-device compute; on the other, a deeply entrenched cloud inference moat that creates webs of ecosystem lock-in across everything from model architecture to chip design.
Appendix
The Math Behind OpenAI’s Memory Overbuying
Comparing the total number of memory wafers OpenAI is buying to the total compute capacity it plans to build out provides a baseline for understanding the supply and demand balance of memory wafers in AI applications. Note that there is some confusion among speculators as to whether OpenAI has contracted 900K wafer starts per month (as stated in its initial press release) or 900K memory chips per month (hundreds or thousands of chips can be created per wafer).
Total Wafers Purchased
Computing the total purchased wafers under OpenAI’s two contracts is fairly simple. The company’s official announcement states that it will be supplied 900K memory wafers per month from Samsung and SK Hynix, but does not specify for how long. South Korean presidential adviser, Kim Yong-beom, said in October 2025 that OpenAI was “seeking to order 900,000 semiconductor wafers in 2029,” but did not clarify how many the company would be purchasing per month in the period between 2025 and 2029. For the sake of this analysis, we’ll assume that the company is buying 900K wafers per month for 12 months only, a likely conservative estimate even assuming some ramp-up over the next four years. This totals 900K * 12 = 10.8 million memory wafers. These wafers are circular and approximately 12 inches (300mm) in diameter, and can be used for many individual DRAM or HBM components.
Total Wafers Needed
Backing out the total number of wafers that OpenAI needs is a more challenging problem. In total, OpenAI’s Stargate computing cluster is estimated to achieve 10GW (up from initial goals of 4.5 GW and 7 GW). Jensen Huang has estimated that Stargate will require four to five million GPUs in total to service 10GW of capacity (Stargate sites have seen 2 million GPUs already delivered).
As of February 2026, the Stargate project has installed Nvidia Blackwell GB200 superchips. Each superchip (assembled as an internal circuit board called the Bianca Board) contains two GPUs (the Blackwell B200 Tensor Core GPU, the B in GB200), one CPU (the Grace, NVIDIA’s ARM-based CPU, the G in GB200), and LPDDR5X DRAM components (along with power and connectivity components).

Source: Nvidia
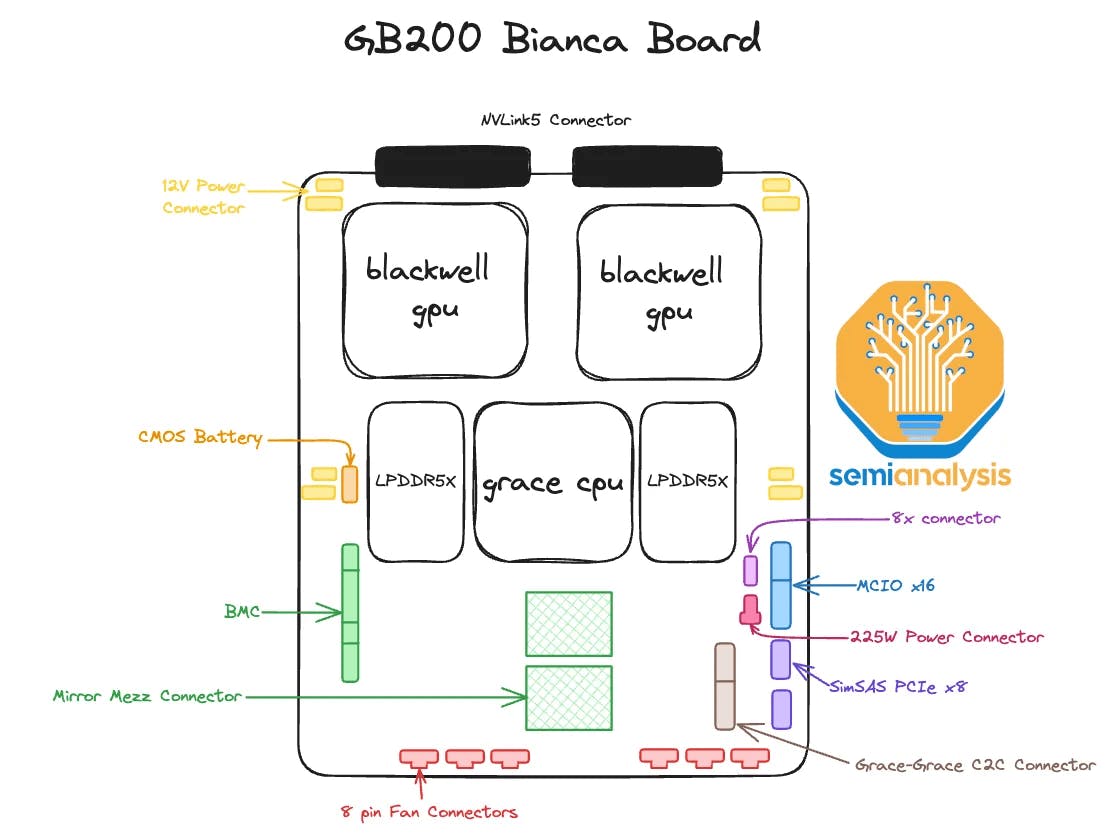
Source: SemiAnalysis
As noted above, each of these components includes memory and will require memory wafers for production.
Blackwell B200 Tensor Core GPU

Source: Micron
Each GB200 Superchip has two Blackwell B200 Tensor Core GPU on board. Each B200 GPU has eight stacks of HBM3e (24GB 8-Hi) built-in alongside the logic processing hardware, totaling 192GB of memory per GPU. Each stack with 24GB of memory is comprised of eight dies, each with 3GB of memory, for a total of 64 3GB dies per GPU. The typical size for a 3GB die is 121 mm², and a standard 300mm DRAM wafer has a usable area of ~70,686 mm². Given the standard formula (accounting for edge losses and scribe lines):
Gross dies ≈ (Wafer area) / (Die area) − (π × Wafer diameter) / (Die edge length)
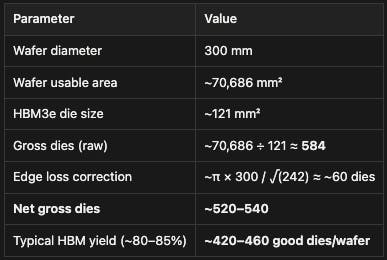
This suggests that one Blackwell B200 Tensor Core GPU with 64 dies requires about 15% of a wafer, so one GB200 Bianca Board with two B200s on board requires about 30% of a wafer.
LPDDR5X

Source: Micron
CPUs like the NVIDIA Grace CPU do not have built-in memory, but instead use the memory embedded on the superchip. Each GB200 Superchip includes up to 480 GB of LPDDR5X DRAM capacity. Despite being cheaper memory than HBM, the sheer capacity requires a massive amount of silicon. The individual LPDDR5X components are made of stacked dies (circuits etched on raw memory wafers). The most common LPDDR5X die density used in high-end applications is 2 GB per die, though NVIDIA has not disclosed the specific die density used in GB200s (some applications also use 4 GB dies).
Assuming that GB200s use 2GB die density, 480 GB of memory requires 240 dies. The number of DRAM dies that can be manufactured per wafer varies from several hundred to over a thousand, depending on the size of the die and the percentage lost to defects. An example 2GB LPDDR5X die is the Samsung K4L6E165YC, manufactured on Samsung's 1a process, which measures 7.50 mm × 6.26 mm = ~47 mm². A standard DRAM wafer is 300mm in diameter, with a usable area of ~70,686 mm². We can use the same calculation as above to find:
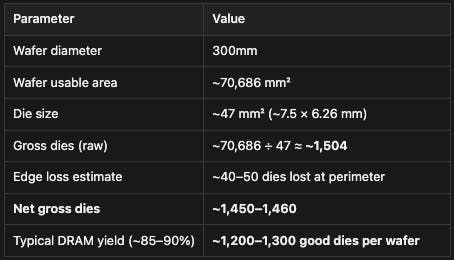
Source: Contrary Research, NVIDIA, TechInsights, Chip Log
This suggests that one GB200 Bianca Board at 480 GB or DRAM capacity requires 240 dies, or 20% of a typical memory wafer.
To recap, each GB200 contains:
Two Blackwell B200 GPUs, requiring around 30% of a wafer (15% each)
480 GB of LPDDR5X capacity, requiring around 20% of a wafer
Estimates that Stargate clusters will require four to five million GPUs don’t clarify whether this number refers to GB200s (each of which has two GPUs on board) or individual GPUs. Some estimates have suggested that one million GB200s (so two million B200s) would require 3GW to power. NVIDIA says that the DGX GB200 NVL72 rack (which contains 36 GB200s, or 72 B200s) consumes 120 kW, including air cooling units. This suggests that a 10GW cluster would be comprised of three million GB200 Bianca Boards, or six million GPUs.
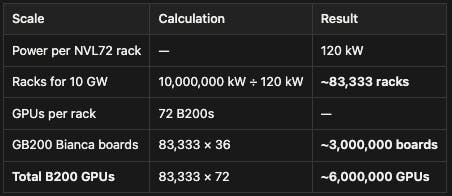
Source: Contrary Research
Assuming that OpenAI really will need three million GB200s, the total demand for memory wafers should be 6 million * (30% + 20%) = 3 million wafers. This is less than 30% of the 10.8 million wafers it’s planning to buy. This is, of course, a rough estimate: OpenAI could buy 900K wafers per month for more or less time than 12 months. The capacity or characteristics of the Stargate cluster could change.
