
In 2026, compute, as opposed to model capability, is the primary bottleneck to servicing demand in the ongoing AI race. Top frontier labs are spending billions to stand up compute clusters at scales and prices that continue to climb. The majority of compute used to service AI demand comes from hyperscalers like AWS and established neoclouds (GPU-focused cloud providers) like CoreWeave.
Besides these incumbents, however, a wave of much smaller neoclouds is entering the market. Some, like shoemaker Allbirds, a whiskey importer, a recruitment website, and a TV production company, have original business models totally unrelated to compute. This piece examines the incentives and demand for new compute providers, the requirements for financing, constructing, and operating a neocloud, and whether the scale and structure of demand for compute will support the success of new, smaller entrants.
Compute Supply & Demand
Goldman Sachs has projected that cumulative global AI infrastructure spending will exceed $7.6 trillion by 2031. While that spend captures networking and connectivity infrastructure, the vast majority reflects the buildout of compute for training and running AI models.
Compute in this context refers specifically to AI-dedicated silicon housed in data centers with qualified power and cooling suitable for both training new AI models and running inference for existing models. Most AI pricing is based on the cost of compute (as measured in tokens), plus a margin, making the cost of compute available the biggest single factor in an AI company's profit.
This differs structurally from SaaS reliance on cloud storage and hosting, though the two are often compared. A SaaS company buys cloud services wholesale and charges its own customers on subscriptions that do not map 1:1 with cloud capacity, allowing SaaS gross margins to run as high as 70-90%. For principally AI companies like Anthropic and OpenAI, compute is the cost of goods sold, leading to lower margins and a more challenging path to profitability. Combined with limited differentiation between models, this makes AI company pricing very sensitive to the cost of compute. Those companies that secure the cheapest reliable compute will have the highest margins when model quality is effectively commoditized.
Compute Demand
The limited supply of compute relative to demand is reshaping competitive dynamics at the frontier of the field. In January 2025, OpenAI announced intentions to spend $500 billion on the buildout of the multinational Stargate compute cluster. In May 2026, Anthropic chose a different route, announcing a deal to spend tens of billions of dollars leasing compute allocation from Elon Musk's xAI, its direct competitor.
While this wave of demand supports record revenues for compute providers, orders have increased faster than companies can increase capacity. Compute brokers have anecdotally described demand as outpacing supply at a 50:1 ratio. Rental rates of four-year-old GPUs like NVIDIA's H100 have started rising in 2026 even amidst meaningfully newer options.
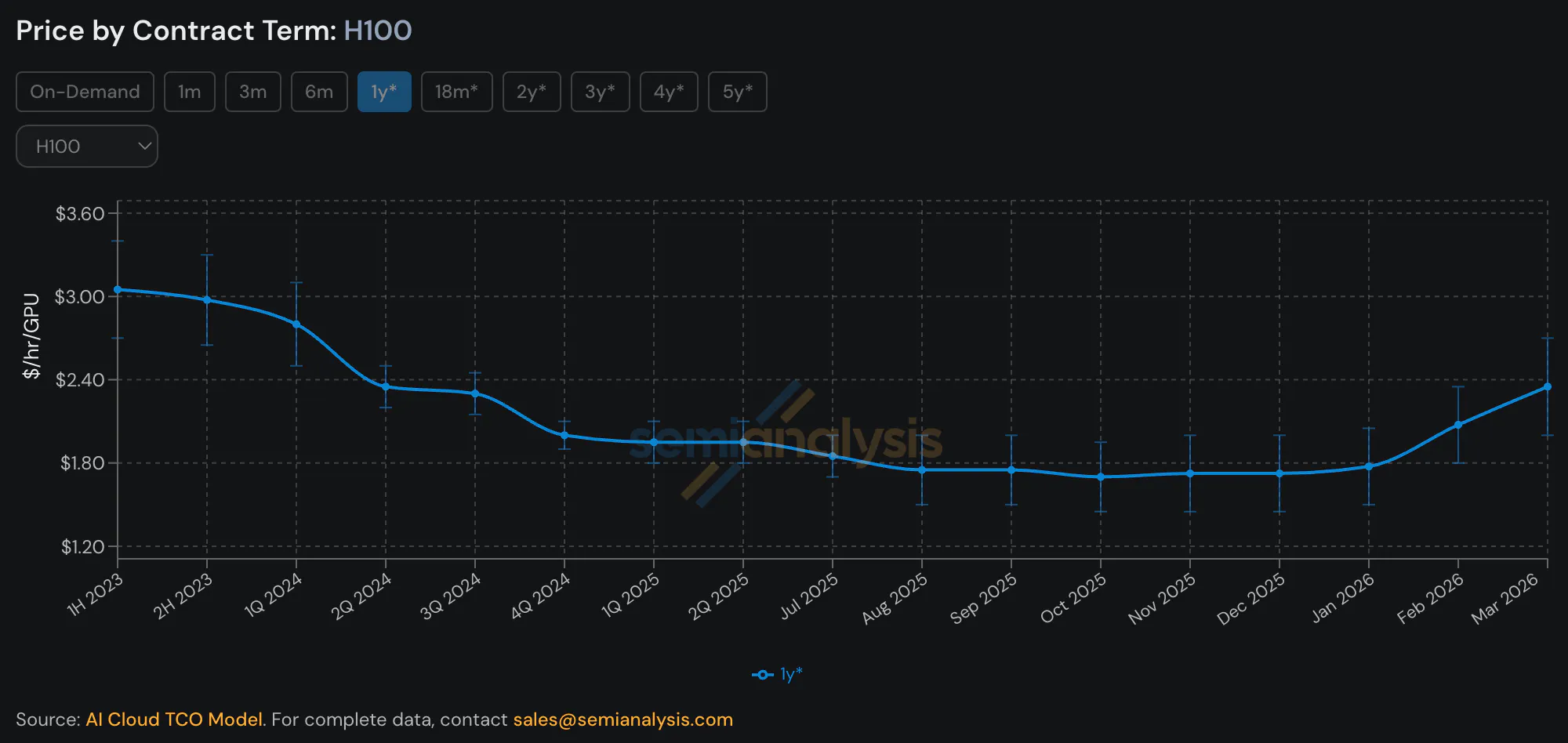
Source: SemiAnalysis
Compute Supply
That hyperscalers cannot keep up with demand is paradoxical: the largest, most-well capitalized players are typically best equipped to scale their operations, access scarce inputs, and finance meaningful expansion. However, large providers gravitate toward large projects: campuses of 100 MW or more that justify their overhead, but that also require utility-scale power, multi-year permitting, and contentious local approvals.
The small pockets of power sitting idle behind existing interconnects at industrial sites are not worth a hyperscaler's attention because they are scattered across the grid and are only several megawatts in scale. A waste-to-energy plant with a consistent 2 MW on-site output is a rounding error to Microsoft, but is a real, immediately deployable opportunity for a small operator. The opening for newcomers to compute supply is not in out-building the largest players, but in aggregating the small pockets of capacity that larger players pass over.
These newcomers come from a variety of backgrounds. Some are ex-crypto miners: companies that built large-scale power infrastructure during the crypto boom and already have the hardware expertise, the power contracts, and the facilities to retrofit for GPUs. Some are real estate operators with access to scarce inputs: usable land, transformer capacity, grid interconnects. Some, like Allbirds, are entrepreneurs working in other technologies, pivoting after seeing the demand. All are pursuing the same opportunity: selling picks and shovels into the AI gold rush.
Whether most of these newcomers survive is an open question. Hyperscalers have advantages that compound over time, and the history of cloud infrastructure consolidation suggests scale wins over the long term. But the speed of AI demand growth and the unique requirements of compute may make these newcomer neoclouds more viable than the cloud era precedent suggests.
Setting up a Neocloud
Financing
The AI infrastructure build-out by neoclouds is primarily funded by debt, not equity. Compared to equity investors, credit committees prioritize capital preservation over high returns. While debt for data centers and new power projects can be underwritten at 15-year lifespans, GPUs are too short-lived to satisfy credit requirements; lenders heavily discount GPUs as collateral due to depreciation risk and instead focus on the offtake contracts as collateral.
Neocloud financing is typically structured via special purpose vehicles (SPVs), dedicated entities that hold the offtake contracts and GPUs. The neocloud manages the SPV, but ultimate financial control sits with the lenders and investors. If the operator defaults, the lenders and investors can take control of the SPV to collect on the offtake revenue and recover their capital. As a neocloud scales, the quality of its clients can improve the company’s financing terms, allowing it to offer compute at a lower price and attract more creditworthy clients.
For newcomer neoclouds, however, there is a Catch-22. Many compute buyers will not commit to a binding offtake contract without first seeing the chips in a facility. But the neocloud cannot buy chips or sign a colocation lease without financing, and it cannot get financing without signed offtake. Only a small number of neoclouds land quality offtake as part of their first deal, making it difficult to get off the ground.
Hyperscalers, by contrast, are funding their build-out with their own equity, projected to spend $5.3 trillion of their balance sheet on AI infrastructure by 2030. Their motivations differ sharply from those of private credit firms seeking fixed income streams. Hyperscalers view losing the AI race as an existential threat to their core businesses.
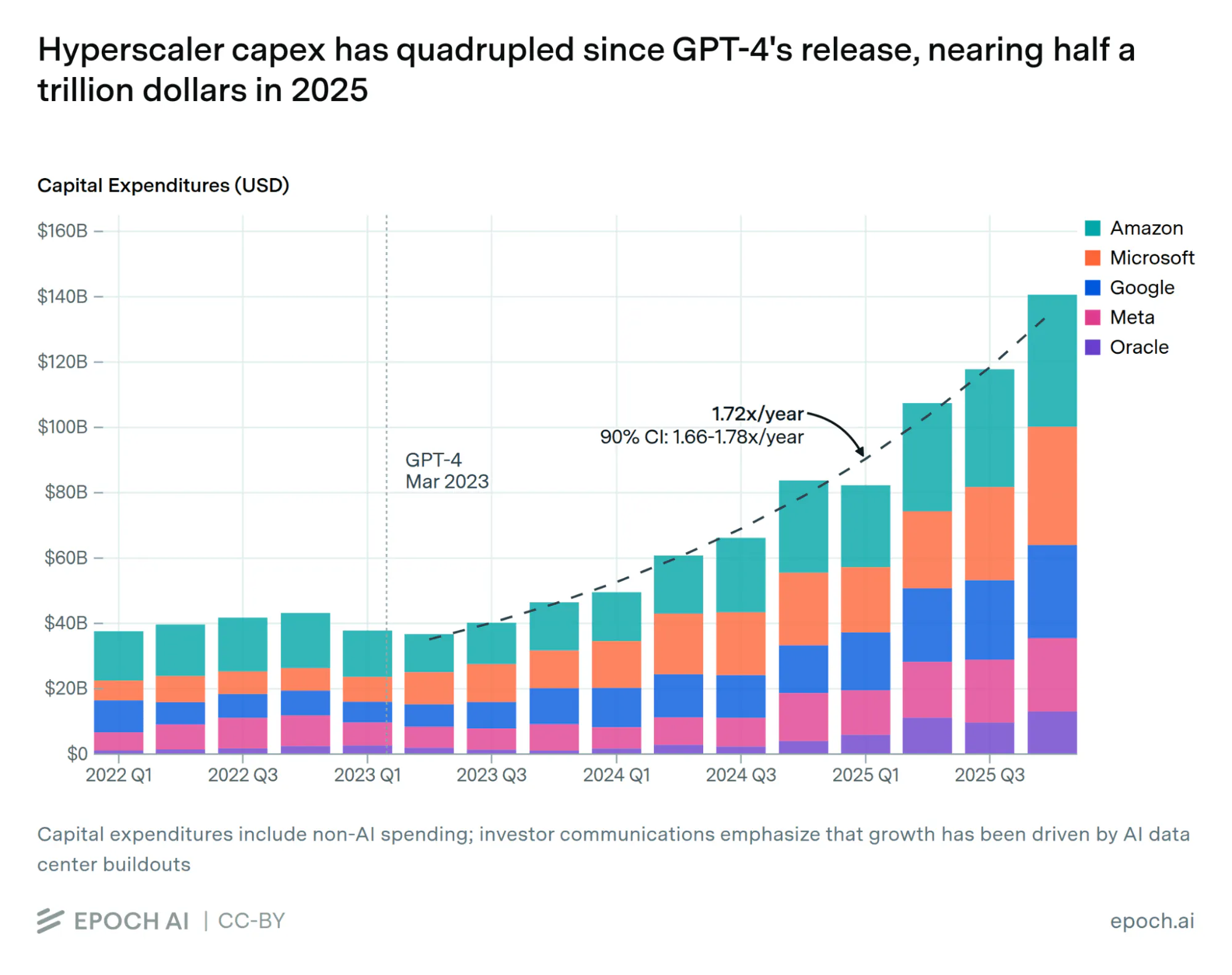
Source: Epoch AI
Offtake
Compute is primarily sold as "offtake": long-term contracts with take-or-pay terms. Under these structures, the buyer pays the contracted price regardless of how much compute they actually use, with penalties for under-utilization. While compute can also be bought on demand, take-or-pay is the primary pricing method because it creates revenue certainty. As noted above, that revenue, rather than data center hardware, is what makes neocloud CapEx financeable.
Offtake contracts can be characterized across four dimensions: price (the hourly rate per GPU), quantity (cluster size, usually measured in megawatts, GPU count, or server count), term (length of commitment, with multi-year strongly preferred), and credit profile of the offtaker
Term and credit are the most important dimensions. A six-month term at a strong rental rate might not renew, leaving the lender in the red. A signed $100 million offtake contract is worthless if the buyer only has $1 million in the bank and cannot pay. CoreWeave's $35 billion offtake contract is one prototypical example of a strong contract: a seven-year term with an A-rated credit counterparty.
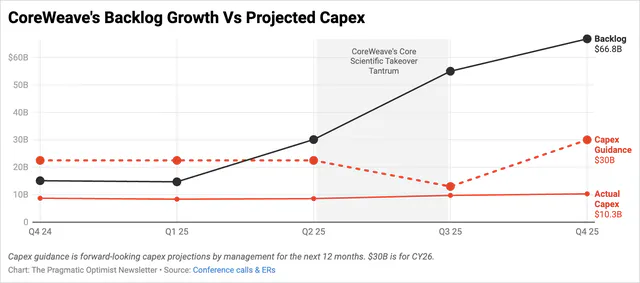
Source: The Pragmatic Optimist
Sorting by Size
Compute buyers exert pressure on both new and existing providers for favorable prices and terms. Competitive buyers want to negotiate rates below those offered by established players like CoreWeave and Nebius, expecting emerging neoclouds to match or undercut these rates to compete.
This expectation, however, ignores critical differences between buyers of compute, and critical differences between the sellers. Market leaders like Nebius would not give most buyers compute allocation in the first place (preferencing their compute for larger and more creditworthy buyers), leaving buyers with no choice but to pay more with alternative compute providers. Established neoclouds can also offer better prices because they are financed at 9% interest rates, while newcomer neoclouds pay 11% or more on debt.
On term, buyers hesitate to commit. Few will sign contracts longer than 12 months, wary of locking in GPUs that become outdated or drop in price. Offtake quality also correlates strongly with cluster size, as larger clusters attract better offtakers: AI labs with billions in funding and Fortune 500 buyers have no interest in stitching together hundreds of small deployments. Below 1 MW, offtake quality is highly mixed.
Buyer credit, which is largely driven by buyer size, drives this sorting. Lenders underwrite neocloud debt on what they call "look-through credit": they look past the neocloud itself, to the credit profile of its end buyer. A $100 million equipment loan clears the credit committee easily when the offtaker is a Fortune 500; it stalls when the offtaker is a seed-stage startup. The arrangement that emerges is symmetrically segmented: creditworthy buyers flow to large providers who can finance against their credit cheaply, while smaller, less-creditworthy buyers pay higher rates to smaller providers, who are the only ones that will serve them.
As of June 2026, most Series B+ AI startups are looking for 2 MW or more. Some sub-1 MW offtakers are still high quality, like hospital groups and universities, but they typically only need a handful of servers under 0.1 MW. Some larger neoclouds also resell compute from smaller newcomers, white-labeled for the end-buyer. Whether that reselling persists is questionable. With demand far exceeding supply, a large neocloud will source third-party capacity to serve customers who need compute immediately. But once it has the capital and pipeline to build its own clusters, it has little reason to hand margin to a third party. Reselling resembles a demand-overflow phenomenon more than a durable channel for the newcomers supplying it.
Space (with Power and Cooling)
If creditworthy, consistent offtake can be secured, the remaining bottleneck is space equipped with the requisite power and cooling. Even with a signed offtake contract in hand, an operator still needs a location with the requisite power and access to cooling and fiber hardware to place and operate chips.
Operators historically relied on colocation providers like Digital Realty or Equinix. A colocation leases physical space for servers with bundled power and cooling in the contract. Even hyperscalers like Google rely on colocation sites for additional capacity. As of 2026, however, almost every colo in the U.S. and Canada is fully booked. The response from hyperscalers has been to build more data centers, but new builds are slow. Local opposition to environmental impact and increased power costs has stalled projects across the country. Utilities across North America are quoting lead times of 4-7 years for grid connection and refusing requests outright. Even resurrecting retired natural gas plants, the fastest meaningful source of power, has not been enough.
Several workarounds have emerged.
Behind the meter. Build power on-site, usually natural gas turbines, and skip the utilities entirely. This is the most common method, exemplified by xAI's Tennessee campus. But the equipment itself is a bottleneck. GE Vernova and Siemens Energy are quotinG 3-4 year lead times for turbines, with most of the 2028-2029 production calendar already sold.
Retrofitting. Take existing industrial buildings with power and rebuild them as data centers. This is where ex-crypto mining operators have been excelling: they already own facilities with sufficient power and cooling from crypto mining.
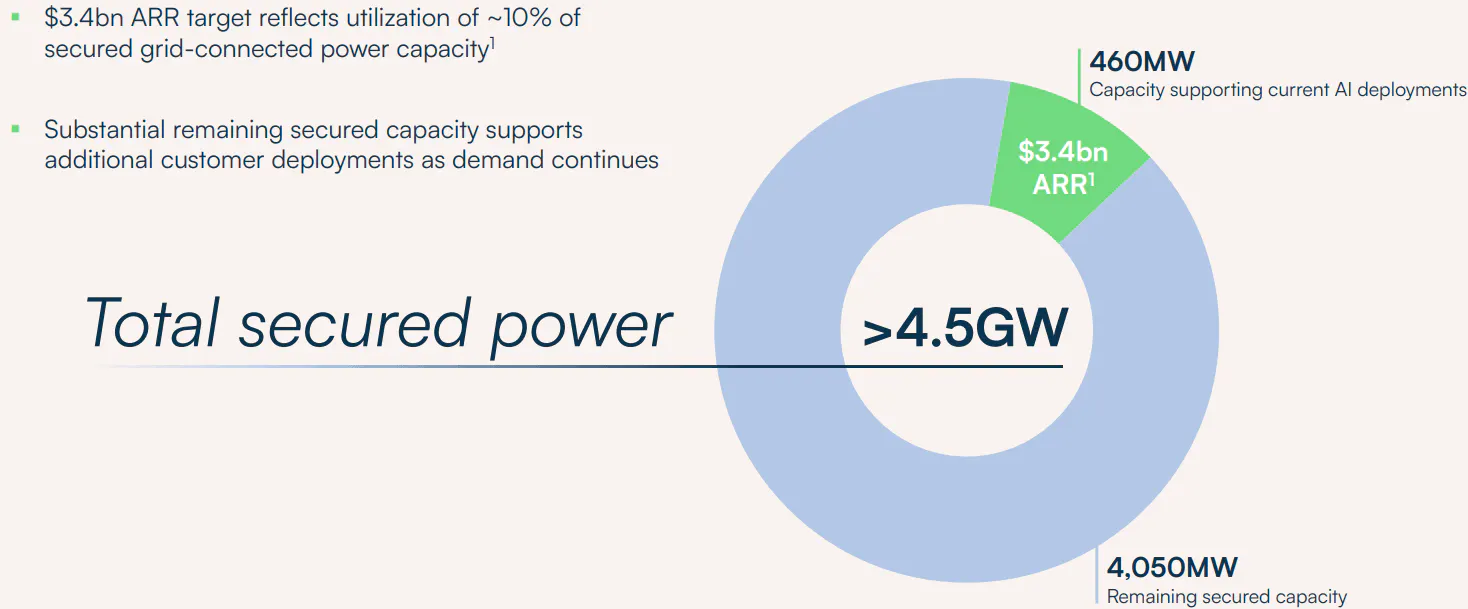
Source: Seeking Alpha
Modular data centers. Use prefabricated units that ship as 20ft or 40ft shipping containers and plug into spare pockets of power in the grid. The deployment timeline is much quicker, but the format only supports smaller cluster sizes, not large MW projects. Some providers are exploring orbital or undersea data centers, which extend this logic to areas with plentiful space but new hardware challenges.
Overseas. While AI demand is concentrated in the U.S. and China, the space can exist elsewhere. Nordic countries offer cheap hydro and geothermal power, while Asia offers more permissive local regulation. This works for AI workloads that tolerate latency (training or agents), compared to more latency-sensitive use cases like live-streaming 4k video.
Qualified space gives some newcomer neoclouds a "right to play". Ex-crypto operators already own retrofittable shells, and real estate developers already control land with usable interconnects. International entrants can tap power the US market cannot access. This opportunity window will close when new builds come online, giving newcomer neoclouds only 3-5 years to establish a meaningful presence before facing the superior economies of scale found in large builds.
Chips
A common misconception is that GPUs are still hard to come by. This was a real constraint in 2025, when lead times stretched past six months and allocation was scarce. Manufacturers and the broader semiconductor industry were caught flat-footed by the speed of AI demand. TSMC's CoWoS packaging capacity has expanded dramatically for the chips, and the industry's memory output has since ramped, such that this is no longer a concern as of June 2026. New NVIDIA B300 servers can be ordered from a value-added reseller (VAR) or original equipment manufacturer (OEM) with a 10-20% down payment and an 8-16 week lead time.
This is an important fact for neocloud entrants. GPU servers are the most expensive part of the AI infrastructure, costing more than the facilities themselves. This means that without a sufficient supply of GPUs, new players would be locked out of the data center market entirely.
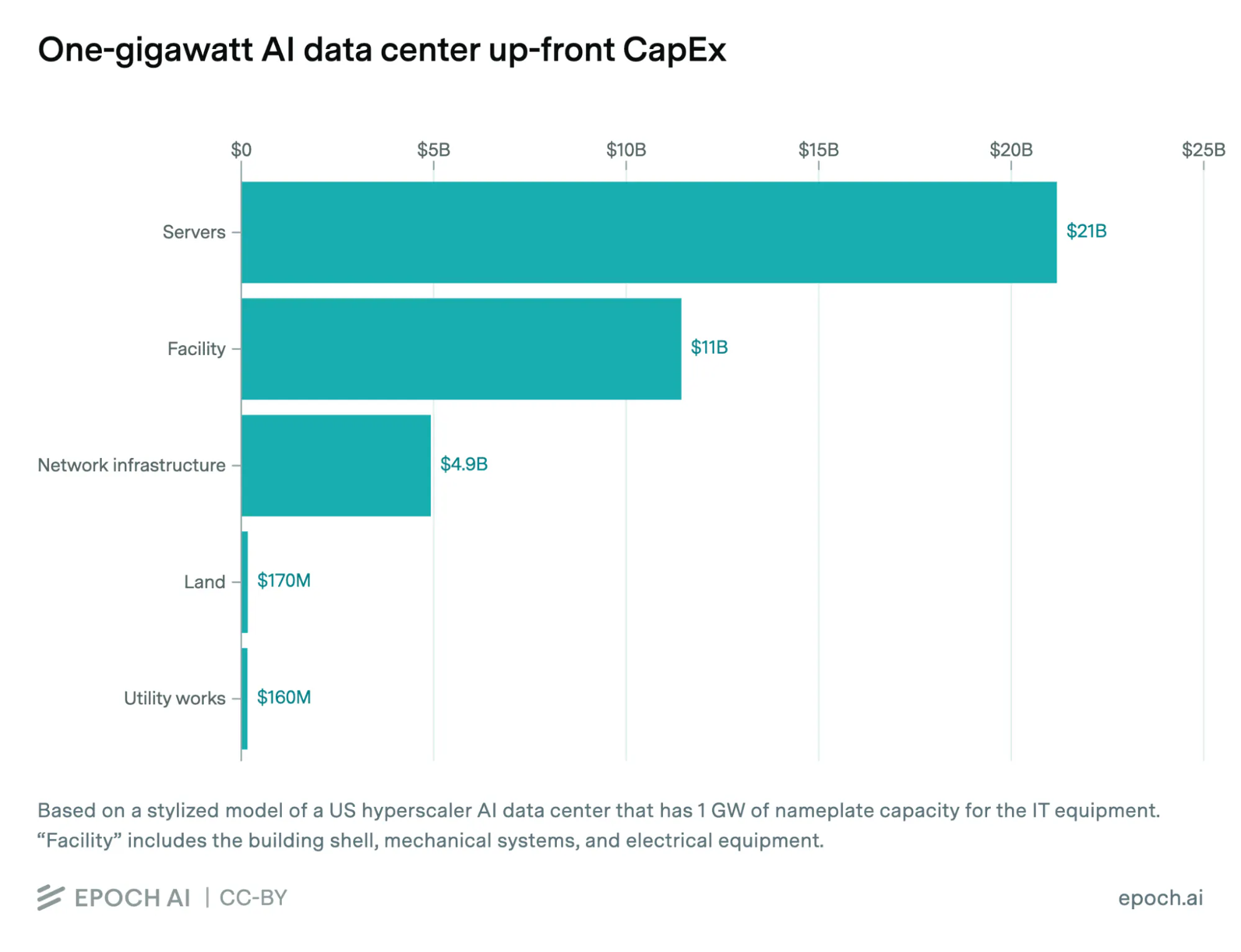
Source: Epoch AI
Demand for chips is spread across GPU generations. While the latest generations command the highest offtake rates, the older NVIDIA Hopper H100s are still renting at around $2.00 per hour as of June 2026. Not all workloads need the strongest available compute, meaning that four-year-old H100s still meet the requirements for a wide range of workloads.
The side effect is that liquidity in the secondary market for used GPUs has dried up. Operators with used inventory are hoarding the chips, including hyperscalers like Meta. Decommissioning partners report that the used GPUs that would once flow to them for resale or recycling have stopped arriving. The logic is straightforward: with demand at 50:1, an H100 earning $2.00 per hour is worth more in an operator's own racks than as cash on its balance sheet, and selling used inventory today means fueling a competitor tomorrow. The result is that it is currently easier to buy a brand-new B300 than a used H100.
The Future of Neoclouds
The market is barbell-shaped today. A few leading neoclouds like CoreWeave, Nebius, and IREN absorb most of the capital and demand; they have unlocked structural advantages that let them scale faster. At the same time, many small newcomers are deploying their first GPU clusters. Midsized providers are missing from the market, and very few newcomers have scaled dramatically.
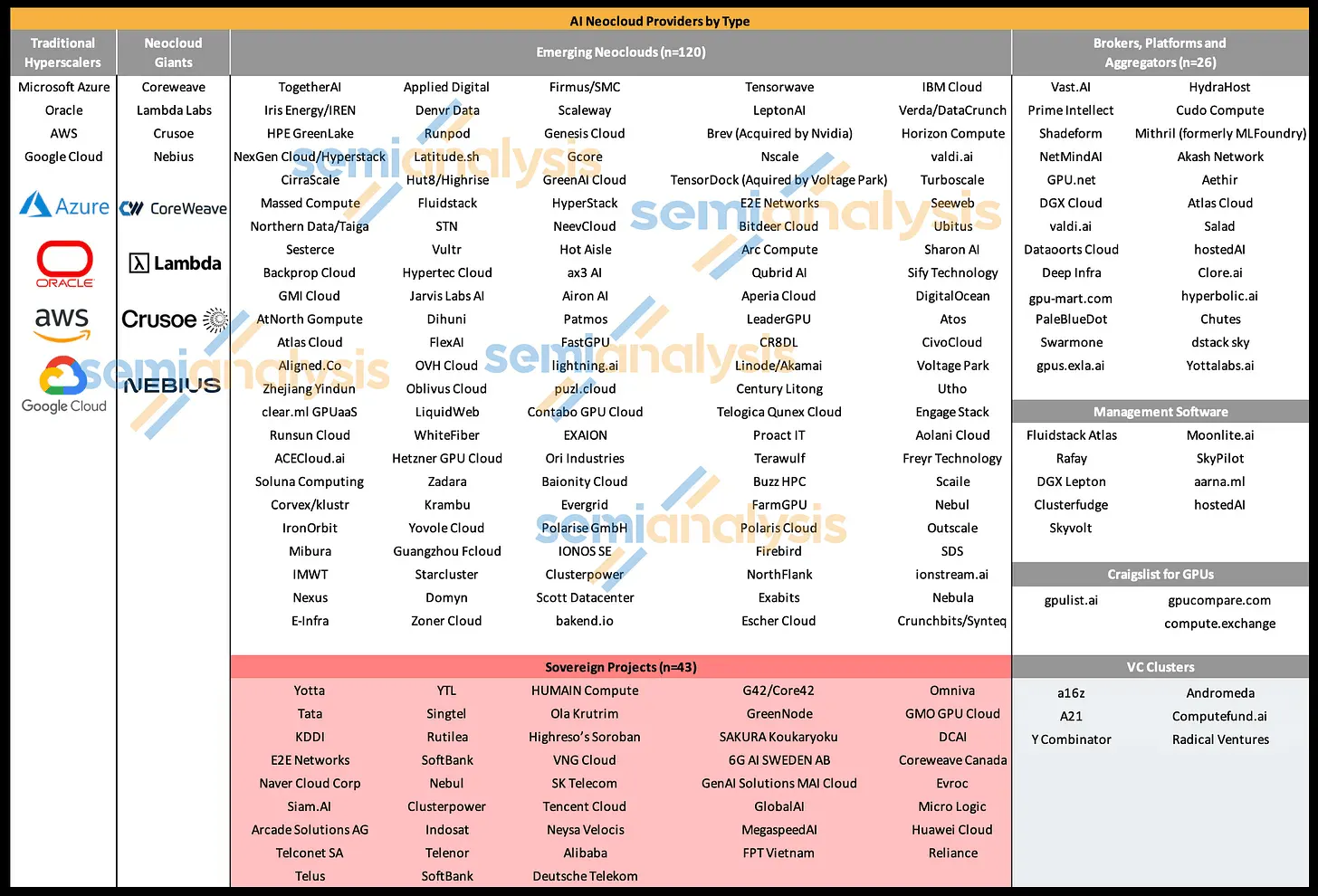
Source: SemiAnalysis
The cheapest compute is also only half of what AI companies are optimizing for. The other half is volume: the AI race is won by whoever secures the most compute, and an inability to scale (or a provider that cannot reliably serve every customer willing to pay) is just as threatening as thin margins. This is the established players' deepest moat. A buyer who needs 50 MW next year knows CoreWeave, Nebius, or IREN can execute the deployment; a newcomer's promise carries execution risk that no rate discount fully offsets. The largest contracts will keep flowing to the providers already proven at scale.
AI application pricing being usage-based, instead of subscription-based, makes compute costs central to AI margins. AI companies will not accept AWS-style high-margin pricing, even when bundled with the kind of additional services that justified premiums in the cloud era.
The evidence of this pricing behavior is that "bare metal", or compute with no extra software installed, is now the most popular form of buying compute. AI companies would rather bring their own software than pay a premium for someone else's or use dedicated inference platforms. Many prefer to access the hardware directly with virtualization, but do not want to own an expensive, depreciating asset.
Bare metal is, by definition, undifferentiated: GPU hours stripped of the integrated services and proprietary software that justified AWS premiums in the cloud era. To be precise, bare metal is not one market but many discrete sub-markets, varying by cluster size, networking choices, SKUs, and manufacturers. That heterogeneity is why financial instruments like compute futures remain premature; there is no single fungible unit to trade.
But heterogeneity is not defensibility. NVIDIA and Dell will sell to anyone, and anyone can choose InfiniBand or a particular node configuration. Unlike EC2, no bare-metal configuration creates lock-in. The variation complicates pricing without protecting margins. If GPU pricing collapses to a price-per-hour-per-GPU benchmark, the structural advantage of being smaller mostly disappears. In that end state, neocloud margins will compress, and thin-margin service businesses consolidate quickly, as airlines, utilities, and telecom did.
Consolidation is likely coming to the data center market. Established hyperscalers and leading neoclouds have cheaper capital, even if offtake, chips, and space are within reach of newcomers. For investors, that means treating neocloud exposure with caution: this market will likely crown only a handful of winners, and the consolidation ahead is more inevitable than most are pricing in today. Newcomer neoclouds have a 3-5 year window to build to scale, get acquired, or wash out.





