
Thesis
Frontier AI model development has created unprecedented demand for high-quality human feedback. As large language models LLMs advance beyond pre-training into alignment and refinement phases, AI labs face a fundamental bottleneck: they need thousands of domain experts to evaluate outputs, write preference data, conduct red-teaming exercises, and build reinforcement learning environments. Traditional recruiting firms take months to source specialized talent, while commodity data-labeling platforms like Appen offer volume but lack expertise. This structural mismatch between the need for expert deployment from AI labs and the market's inability to deliver it efficiently has created an opportunity for new, two-sided marketplaces to connect knowledge workers with model developers.
The industry’s dynamics are shifting toward post-training human intelligence. Since 2024, models like OpenAI’s o1 have achieved state-of-the-art performance through reinforcement learning from human feedback (RLHF) and iterative refinement, rather than relying solely on raw pre-training scale. While pre-training requires massive one-time compute investments, post-training demands ongoing expert feedback. As models approach similar pre-training capabilities, differentiation increasingly comes from the quality and volume of human feedback during alignment. With major labs racing toward AGI, data represents an existential competitive advantage in this AI arms race, expanding the total addressable spend on human feedback.
The rise of agentic AI and autonomous systems is also creating entirely new categories of demand for expert feedback beyond traditional RLHF. As AI systems move from answering questions to taking actions, the evaluation surface area explodes. Agents will now need to write code, conduct research, and make financial decisions. This means labs need experts who can assess not just linguistic quality but also domain-specific correctness, safety boundaries, edge-case handling, and multi-step reasoning chains.
Constitutional AI requires political scientists, medical AI requires physicians to evaluate clinical reasoning, legal AI requires lawyers to assess precedent application, financial AI requires analysts to validate investment logic, and code generation requires senior engineers to review architecture decisions. Each new capability domain requires its own specialized feedback pipeline, and the scope of required expertise compounds as models become more capable. The global knowledge work economy exceeded $40 trillion as of 2025: if even 1% of this becomes addressable for AI feedback loops, it represents a $400+ billion annual opportunity.
Mercor aims to serve as critical infrastructure for this transformation. Originally founded as a recruiting marketplace, the company executed a strategic pivot that transformed it into the expert service layer for frontier model development. Mercor's AI-powered vetting system conducts structured 20-minute video interviews to source, screen, and deploy hundreds of domain experts.
As of February 2025, the platform had evaluated 468K applicants and built a proprietary dataset on talent quality, creating compounding advantages. Better vetting leads to higher-quality placements, further improving matching algorithms by generating performance data. As post-training becomes a primary driver of model differentiation and AI labs race to secure access to specialized human intelligence, Mercor looks to own the talent layer that makes frontier AI development possible while building network effects that become harder to replicate with each successive placement.
Founding Story

Source: Mercor
Mercor was founded in January 2023 by Brendan Foody (co-CEO), Adarsh Hiremath (former CTO, co-CEO), and Surya Midha (former COO, Board Chairman). Hiremath and Midha grew up as childhood friends and met through elementary school debate tournaments. All three co-founders attended high school at Bellarmine College Preparatory in San Jose, where they were teammates on the school's nationally ranked speech and debate team.
After graduating in 2021, Foody and Midha enrolled at Georgetown University while Hiremath went to Harvard. As 19-year-old sophomores, they identified that the global hiring market was incredibly inefficient, particularly for technical talent that came from outside the US. When Foody attended a hackathon in São Paulo, he realized they could match companies with skilled engineers abroad, handle logistics, and take a cut of the fees companies pay engineers for their services. The new company’s first client paid $500/week for a developer, and it kept roughly 30%.
The initial product manually paired skilled developers from India with US startups via WhatsApp and Google Sheets, all run from the co-founders' dorm rooms. Within months, they had bootstrapped to $1 million in annualized revenue and built a talent pool of 100K users across 25 countries. By mid-2023, the co-founders realized these manual processes could not scale, so they built an internal AI interviewer tool to conduct 20-minute structured video assessments. This transformed Mercor into a technology-powered hiring platform.
A second, more consequential shift occurred from 2024 to 2025, when Mercor expanded from AI recruiting to AI training infrastructure. As frontier labs like OpenAI, Anthropic, and Google required domain experts for model post-training via RLHF, Mercor's vetted expert network became an ideal source of supply. In March 2024, all three co-founders were awarded the Thiel Fellowship, and they subsequently dropped out of college permanently.
The company experienced rapid growth over the next year, all with a lean internal team. When Mercor achieved $50 million ARR, the company had just 30 full-time employees in the US and 20 contractors in India. By February 2025, the company reached $75 million ARR and had helped HR teams evaluate over 468K applicants. As the company scaled, it brought in experienced executives to guide the next phase of growth. In May 2025, Mercor hired Sundeep Jain as President, bringing with him expertise from his time as CPO and SVP of Engineering at Uber and prior experience as VP of Product Management at Google, overseeing Search Ads. Mercor achieved $450 million in ARR when it raised its Series C in October 2025, making all three co-founders the youngest self-made billionaires in history at age 22.
Product
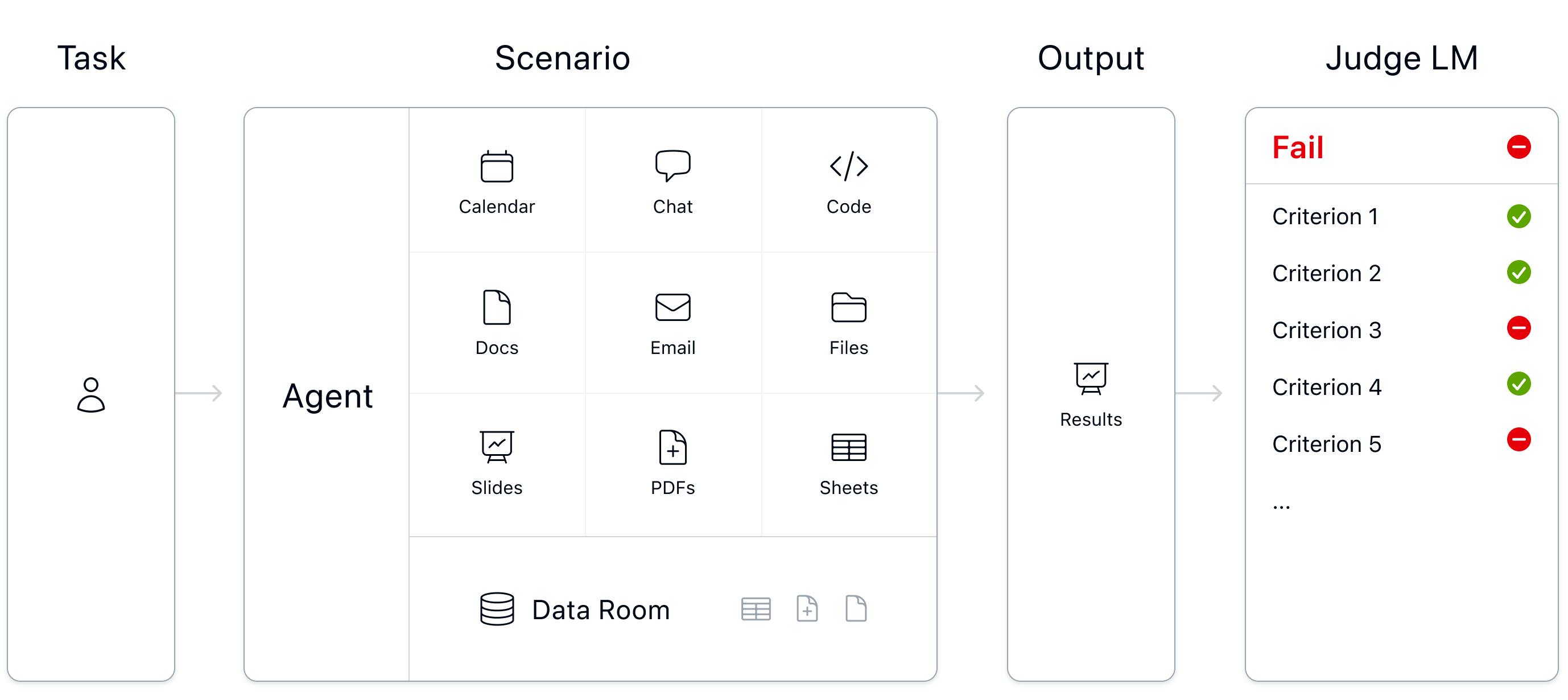
Mercor is an AI training data platform that connects frontier AI labs with domain experts for post-training work, including RLHF, supervised fine-tuning (SFT), model evaluation, rubric development, and reinforcement learning environment construction. The company’s model provides access to over 30K experts across domains such as investment banking, medicine, management consulting, law, and scientific research.
Platform Infrastructure and AI Interview System
While Mercor’s revenue is primarily derived from expert-provided data for AI training, the platform’s underlying infrastructure includes an AI-powered candidate vetting system that sources and qualifies the expert network. Workers begin by creating a profile, browsing available position listings on the platform’s Explore page, and filtering by job fit, pay, or recency.
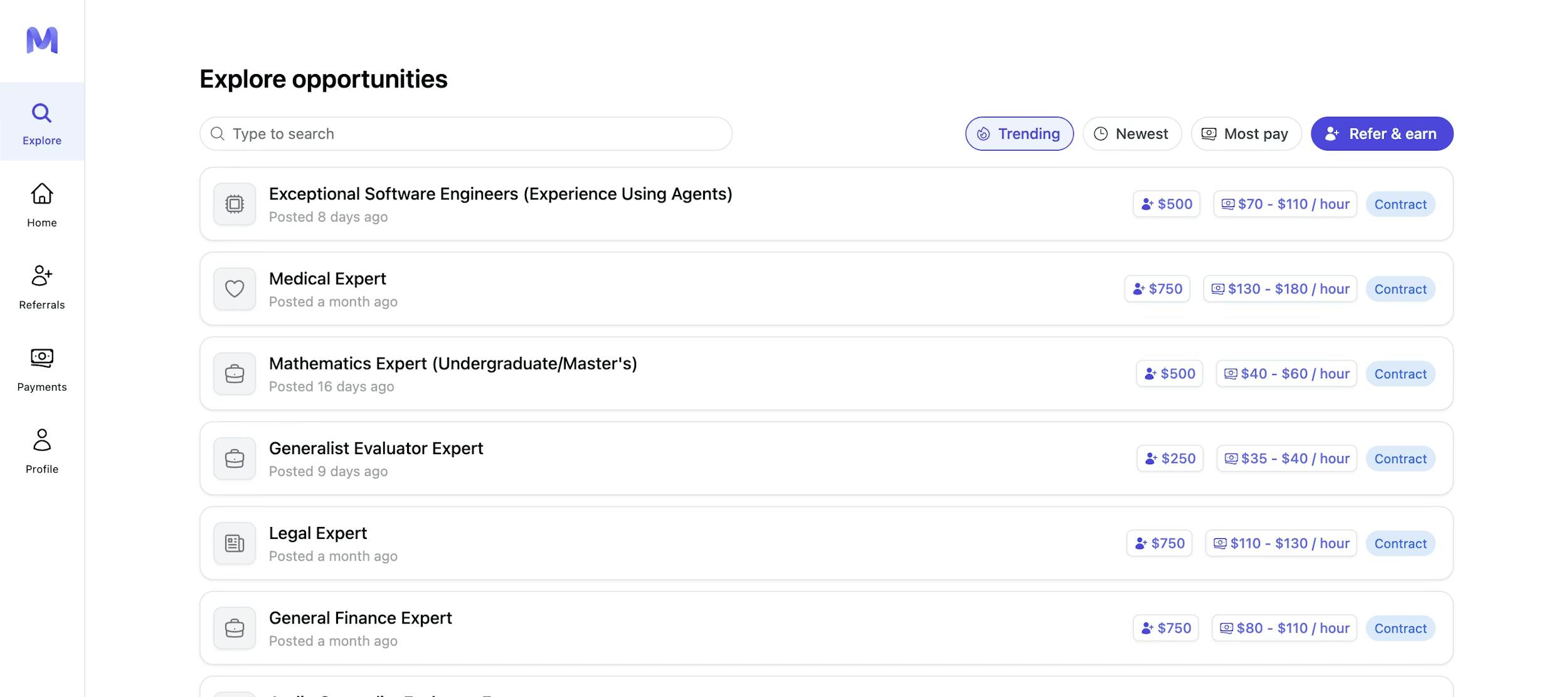
Source: Mercor
Every candidate then completes a customized 20-minute video interview conducted by an AI voice agent that reviews resumes, gauges specific skills, and asks follow-up questions. The agent evaluates technical depth, reasoning ability, communication clarity, and domain expertise beyond what resumes convey. Candidates can retake interviews up to three times, and some roles include written exercises analyzing AI prompt-response scenarios with rubrics before the video stage. Successfully completed assessments are reused across compatible roles, meaning a physician who passes a diagnostic reasoning evaluation does not need to requalify for each successive project. This reduces the friction for high-quality experts while compounding the platform's data advantage on their performance over time.
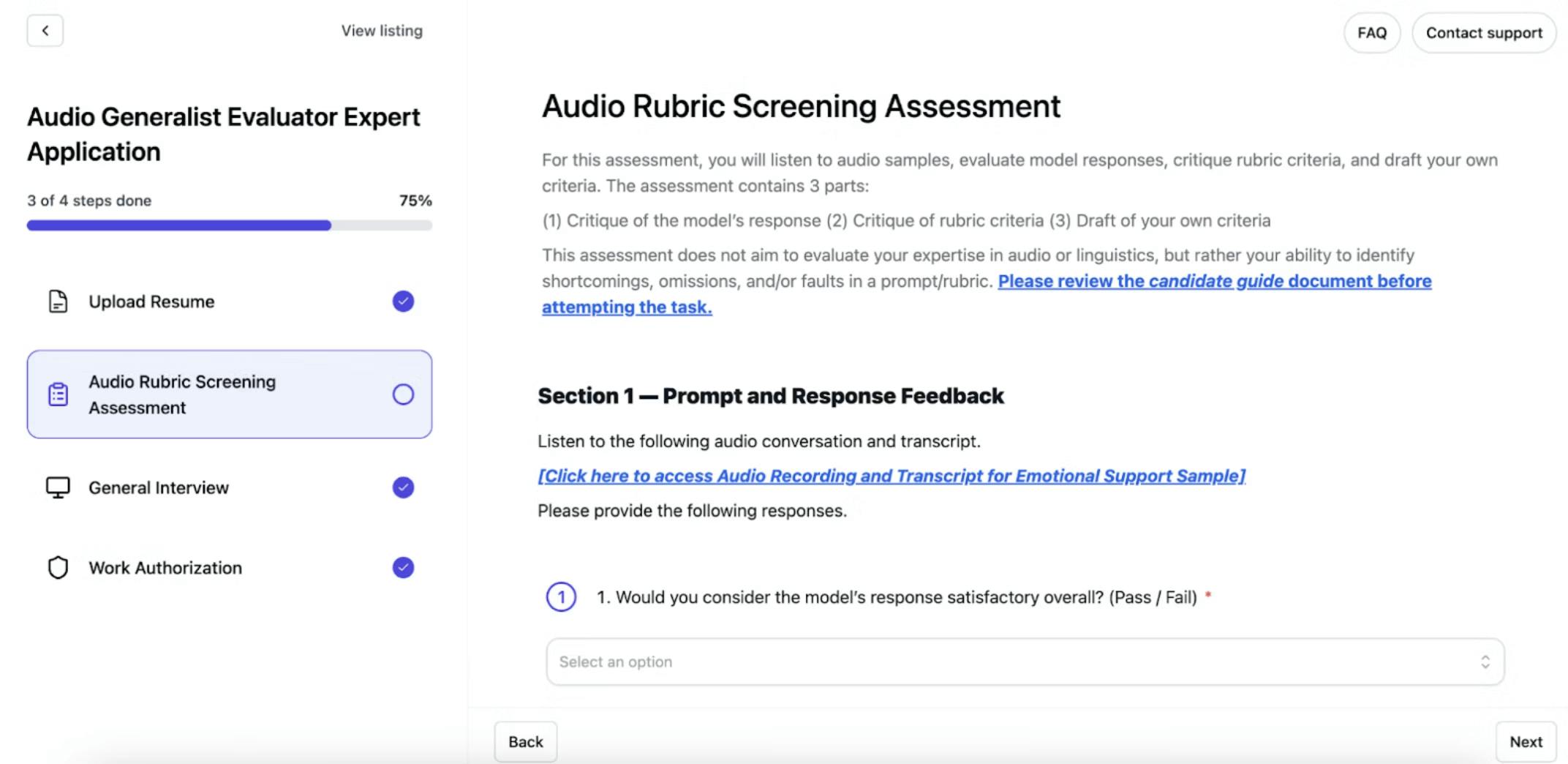
Source: Mercor
Upon selection for a project, workers move through a structured onboarding checklist before they can begin logging hours. This includes identity verification via Persona, a background check through providers like Certn, signing a Terms of Work agreement and a Confidentiality and IP Assignment Agreement, completing a W-9 or W-8BEN tax form (depending on residency), and setting up payment through Stripe (or Wise for contractors in regions where Stripe is unavailable). Some projects additionally require Okta SSO setup for secure access to client tools like Slack. The platform handles integrated contracting end-to-end, and contractors handle their own tax filings (1099-NEC for US residents earning over $600 annually, W-8BEN for non-US workers).
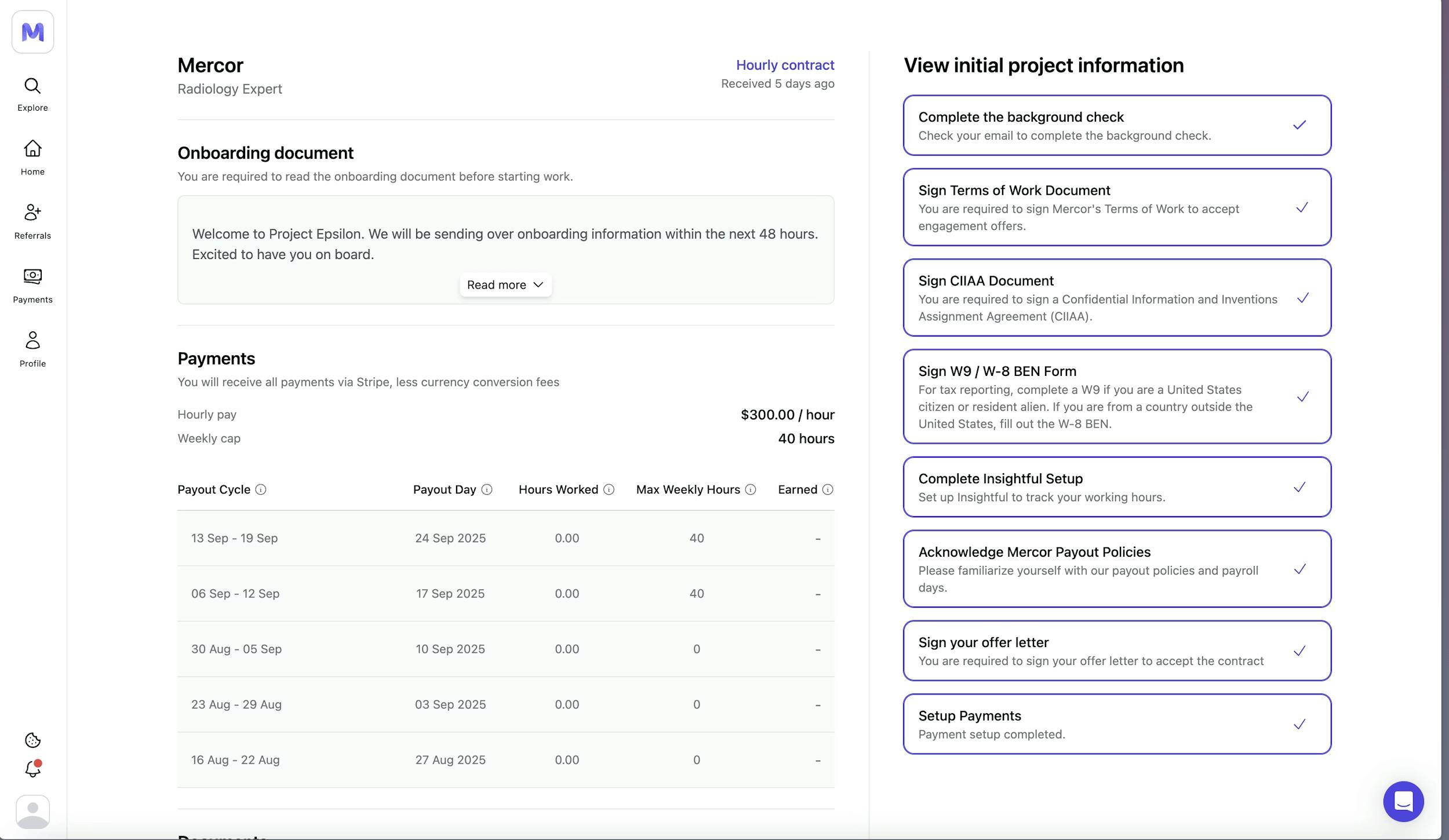
Source: Mercor
Post-Training Data Products
RLHF represents one of Mercor’s core service offerings for AI labs training frontier models. The process involves presenting domain experts with multiple model-generated outputs for the same prompt and collecting structured preference rankings that train reward models to predict human judgment. For a medical diagnosis task, Mercor might source board-certified physicians to evaluate and rank competing diagnostic reasoning chains, annotating which response demonstrates superior clinical reasoning, appropriate differential diagnosis consideration, and patient communication quality. These preference pairs become training data for reinforcement learning algorithms that fine-tune models toward outputs humans judge as higher quality.
SFT requires generating gold-standard prompt-response pairs that demonstrate desired model behavior across specific task distributions. Unlike RLHF's comparative preference rankings, SFT involves creating complete, production-quality responses that models learn to imitate through supervised learning. Depending on the task, this ranges from domain experts writing comprehensive legal analyses or financial models to generalist annotators handling summarization, instruction-following, and conversational tasks that don’t require any specialized credentials.
Rubrics are scoring frameworks that decompose complex quality judgments into measurable, consistently applicable criteria with defined performance levels and descriptors. Rather than treating outputs as binary pass/fail assessments, rubrics assess responses against a set of predefined criteria with varying levels of achievement. A key advantage of rubrics is the ability to identify partial correctness, since an AI response might meet some criteria well while falling short on others. Rubrics can be used by auto-grader LLM systems to help models learn from automated rewards, and because the criteria are explicit and human-readable, they can be worked on collaboratively by domain experts and engineers, then scaled cost-effectively using LLM judges without losing interpretability.
RL environments are simulated work environments where AI agents can execute multi-step tasks and receive reward signals based on outcome quality. For training a customer service agent, this might involve creating realistic help-desk ticket systems with representative issue distributions, customer interaction histories, knowledge base articles, escalation workflows, and corresponding autograders to verifiably score resolution quality across accuracy, response time, and policy compliance. Mercor’s Archipelago evaluation harness, released as open-source infrastructure on GitHub, provides Docker-based systems for running and evaluating AI agents against RL environments.
Source: Mercor
Benchmarks
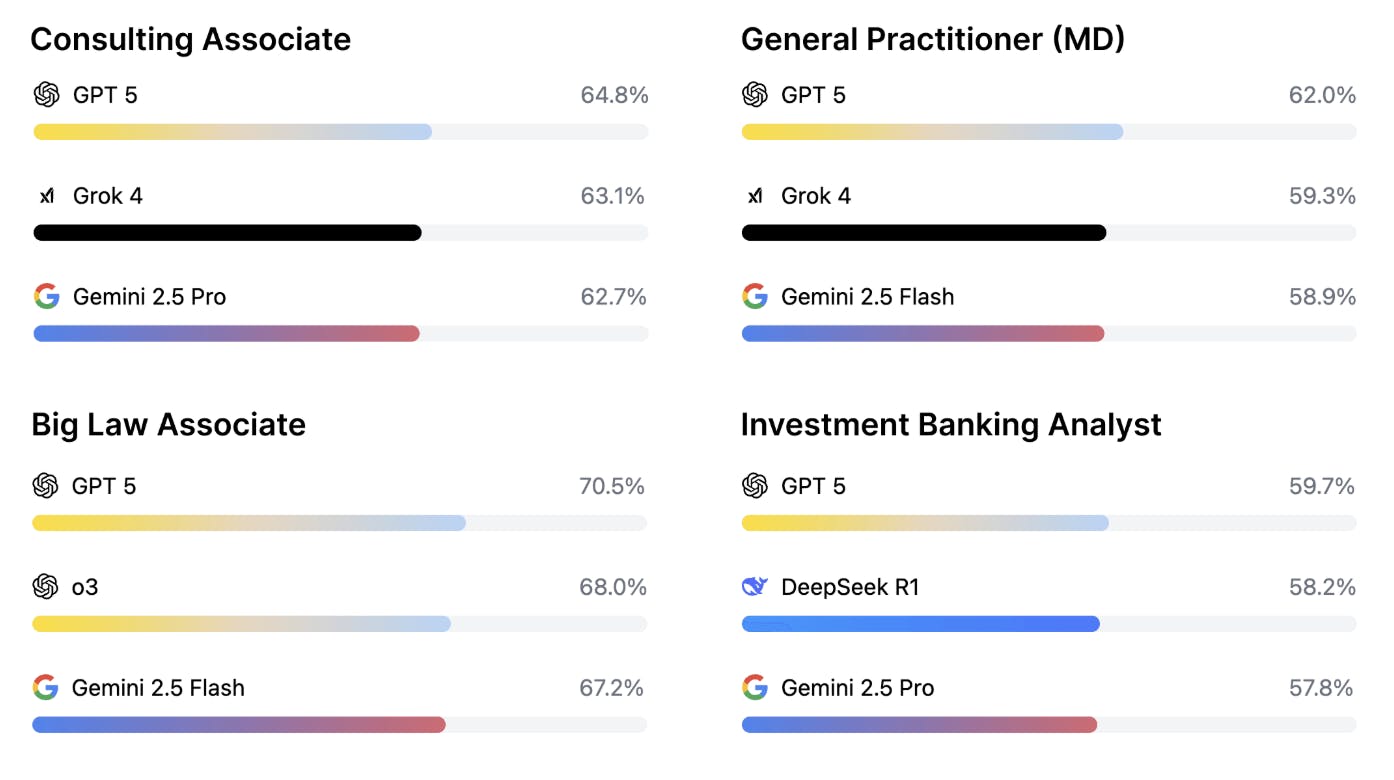
Launched in October 2025, APEX (AI Productivity Index) represents Mercor's entry into evaluation infrastructure as a distinct product line. The benchmark measures frontier AI model performance on real-world economically valuable tasks across four professional domains: investment banking, management consulting, law, and medicine. Version 1.0 covered 200 cases with tasks taking professionals one to eight hours and rubrics averaging 29 criteria per task, developed with approximately 100 experts.
Source: Mercor
GPT-5 achieved a top score of 64.2%, with none of the 21 tested models meeting production thresholds for autonomous professional work. Subsequent expansions include APEX world (RL environments for evaluating how well AI models can actually interact with tools and files) and broadening the professions and task types covered. In December 2025, Mercor expanded the held-out evaluation set from 200 tasks to 400 tasks, with GPT 5, Thinking = High having the highest average score at 67% across the domains.
In December 2025, Mercor released ACE (AI Consumer Index), a benchmark testing consumer tasks for AI across shopping, food, gaming, and DIY-related topics. GPT 5.1 emerged as the top-performing model but only scored 56.1%. For each task, a rubric of prompt-specific criteria was generated to grade model responses in a scalable way. Only after passing a hurdle criterion can further rewards be unlocked, meaning that the model must address a user’s core objective to maximize its received rewards. Grounding criteria were also added to penalize models for making unsupported claims based on the web sources it retrieved or for providing non-functional links. In this way, the benchmark aims to prevent reward hacking and penalize unhelpful model behavior.
Source: Mercor
In January 2026, APEX-Agents was introduced as a new benchmark to test how well AI agents can complete real-world, long-horizon tasks across investment banking, management consulting, and corporate law. To replicate the messy context of real-world tasks, Mercor surveyed hundreds of experts from professional services and created environments to simulate how coworkers would collaborate on projects. Experts then created tasks and grading criteria that would define what a client-ready deliverable would be. AI agents were then deployed inside these worlds to measure whether they finished the work correctly. All frontier models tested completed less than 25% of tasks successfully. With up to eight attempts, the best agents only completed 40% of the tasks.
Source: Mercor
Market
Customer
Mercor serves a two-sided marketplace with the primary stakeholder groups being enterprise clients and expert contractors.
Enterprise clients: Mercor’s enterprise customer base is heavily concentrated among frontier AI laboratories, with the company claiming to work with all of the top five AI labs and six of the Magnificent 7 technology companies as of July 2025. These include OpenAI, Anthropic, Meta, and Google. Frontier AI labs require large volumes of domain experts for generating post-training data, including evaluating model outputs, red-teaming, and writing preference data. Beyond AI labs, Mercor is also expanding into consulting firms, financial services, and enterprises building AI applications that require specialized talent for model evaluation or training.
Expert contractors: Mercor had conducted over 100K interviews and evaluated 468K+ applicants as of February 2025. The active contractor base was reported to be over 30K experts as of October 2025, spanning 45+ countries. India was the largest source of talent, followed by the United States. The contractors on Mercor’s platform span knowledge work domains, including software engineers, doctors, lawyers, bankers, consultants, PhDs, scientists, and journalists. As of October 2025, the average pay for experts was $85/hour, with daily contractor payouts exceeding $1.5 million.

Source: Mercor
Before Mercor, AI labs primarily relied on competitors (like Scale AI), internal data teams, academic partnerships, and commodity data labeling platforms (like Appen), while traditional recruiting firms or freelance marketplaces served the broader hiring market. Mercor’s advantage over these previous platforms was the combination of AI-powered vetting speed for recruiting and access to skilled domain experts in one end-to-end platform. Additionally, the company stood out from other post-training data providers in their early focus on highly-skilled experts.
Market Size
The global staffing and recruitment industry generated approximately $584.1 billion in 2024 and is projected to grow at a 6.2% CAGR to reach approximately $945.1 billion by 2034. Despite its scale, the industry remains inefficient: the average cost per hire reached $4.7K in 2023, while time-to-fill hovers around 63.5 days depending on role complexity. Recruiters spend 13 hours per week per role just sourcing passive candidates and nearly two hours daily on administrative tasks. Within the global staffing market, AI-powered recruiting tools represent a smaller but rapidly expanding segment. The AI recruitment market was valued at approximately $617.6 million in 2024, growing at a CAGR of 7.2% to reach $1.1 billion in 2033.
However, this figure understates Mercor's opportunity, as the company uses AI to capture value across the much larger staffing market. The most relevant frame for Mercor's trajectory might be the AI training and post-training data market, where frontier models increasingly require expert human feedback for reinforcement learning and evaluation. While market sizing is difficult given the segment's nascency, the data labeling industry was valued at approximately $3.8 billion in 2024 and is projected to reach $17.1 billion by 2030 at a 28.4% CAGR. These numbers could still underestimate the value of expert-level human feedback versus commodity labeling: Mercor's leadership frames the ultimate opportunity with the $40+ trillion global knowledge work economy in mind, arguing that if AI automates 90% of cognitive tasks, the remaining human-in-the-loop work becomes exponentially more valuable per unit.
Competition
Surge AI: Founded in 2020, Surge AI operates a post-training data platform that connects frontier AI labs with expert annotators across SFT, RLHF, rubrics, evaluations, and RL environments. The company crossed $1.2 billion in revenue in 2024 while remaining bootstrapped and maintaining profitability since its founding. Surge serves the same core customer base as Mercor, including publicly disclosed clients such as Google, Microsoft, Meta, and Anthropic. It maintains a network of approximately one million annotators. Although Surge lacks Mercor’s AI-driven recruiting platform, it has built a larger, more established operation that touts its data quality.
Scale AI: Scale AI was founded in 2016 to provide data labeling and annotation services for training AI models. The company built the industry's largest data labeling platform, offering human-in-the-loop annotation, synthetic data generation, model evaluation, and multimodal training data. Prior to 2025, Scale raised a total of $1.6 billion across multiple rounds, including a $1 billion Series F in May 2021 at a $7.3 billion post-money valuation led by Greenoaks Capital, Dragoneer Investment Group, and Tiger Global Management. The company generated approximately $870 million in revenue in 2024 and served major AI labs, including OpenAI, Google, Meta, and Microsoft.
In June 2025, Meta invested $14.3 billion to give it a 49% stake in Scale. The CEO of Scale, Alexandr Wang, also departed to lead Meta’s AI superintelligence lab. The deal created immediate concerns around neutrality for its enterprise clients: OpenAI and Google both severed relationships, as Meta is a direct competitor in AI model development. The customer exodus created market openings that Mercor, Surge, and other data providers rapidly captured. Scale also filed a lawsuit against Mercor in September 2025, alleging trade secret misappropriation, claiming a former Scale employee downloaded confidential customer strategy documents before joining Mercor.
Turing: Founded in 2018, Turing connects companies with pre-vetted software developers through AI-powered vetting and matching algorithms. The company underwent a pivot when OpenAI engaged it for training code generation models, expanding beyond traditional developer placement into AI training services. Turing reported approximately $300 million in ARR, was profitable, and raised a $111 million Series E in March 2025 at a $2.2 billion valuation led by Malaysia's sovereign wealth fund Khazanah Nasional Berhad. The platform maintains a pool of over 3 million developers globally. Turing has expanded its focus to include large-scale RL environments and multimodal agent training on economically valuable tasks outside of coding.
Micro1: Micro1 was founded in 2022 and began as an AI recruiter with an AI interviewer named "Zara." The company raised a total of $41.6 million as of February 2026, including a $35 million Series A at a $500 million valuation in September 2025, led by 01 Advisors with participation from Kindred Ventures and Y Combinator. Micro1 pivoted into the AI training and post-training data space, crossing $100 million ARR in December 2025, up from $7 million at the start of 2025.
The company's customers reportedly include Microsoft and multiple Fortune 100 companies. CEO Ali Ansari has publicly positioned Micro1 as competing directly with Scale AI, Surge AI, and Mercor for frontier AI lab customers. The company offers AI-powered interviewing through conversational assessments, semantic matching for candidate selection, and expert sourcing for RLHF and model evaluations. Micro1 maintains a network of vetted experts across technical and domain-specific roles, with its product offering mirroring Mercor's full-stack talent management approach.
Invisible Technologies: Founded in 2015, Invisible Technologies operates at the intersection of AI automation and human-in-the-loop work, offering managed services that combine software, process design, and a global workforce. As of February 2026, the company has raised a total of $144 million, including a $100 million funding round in September 2025. For AI training data, Invisible handles the complete pipeline: task decomposition, annotator sourcing and training, quality control, and delivery of labeled datasets. The company shares Mercor’s focus on providing high-quality human expertise and reached $134 million in revenue in 2024.
Handshake: Founded in 2014, Handshake operates a college recruiting platform connecting students and early-career professionals with employers. As of February 2026, the company raised a total of $434 million, including a $200 million Series F in January 2022 at a $3.5 billion valuation. The platform serves 18 million students and alumni across 1.5K+ educational institutions. Handshake entered the AI data labeling market in 2025. The platform's value proposition centers on mobilizing educated, English-fluent workers for post-training data tasks that require subject-matter expertise. Handshake handles sourcing workers and quality-checking data produced on its own annotation platform for AI labs.
Business Model
Mercor generates revenue by charging enterprise clients in its two-sided marketplace. The revenue model has two primary mechanisms.
Hourly contractor billings: The primary revenue driver for Mercor is charging enterprise clients a marked-up rate for contractors. For ongoing expert engagements (the primary use case for AI labs), Mercor pays contractors an average of $85/hour (with some specialists earning up to $200/hour) and charges clients a marked-up rate. In February 2024, this was reported to be approximately 35%, which aligns with median gross margins for business process outsourcing (BPO) companies.
Placement fees: For permanent talent placements, one unverified estimate says that Mercor charges approximately 30% of first-year compensation as a recruiting fee. This is at the high end of the traditional recruiting agency range of 15–25%, but includes AI-powered vetting, end-to-end contracting, and payroll management that traditional agencies do not provide.
Mercor’s pricing is not publicly disclosed. The company's fixed costs are likely minimal, since the 30K+ experts serve as contractors, not employees. Historically, the company has operated a lean, young internal team to manage client projects and build its automated recruiting platform. When Mercor achieved $50 million ARR, the company had just 30 full-time employees in the US and 20 contractors in India. In February 2025, the company’s average team age was reported as 22.
The key variable cost for the business is contractor compensation, which scales linearly with revenue but is offset by the take rate (which might vary depending on the client or type of work being done). Mercor’s AI interviews replace labor-intensive recruiting, allowing them to scale their workforce without proportionally increasing headcount for vetting. The company was profitable in H1 2025, generating $6 million in profit.
Traction
Revenue Growth
In October 2025, Mercor reportedly claimed it was on track to reach $500 million in ARR (annual revenue run rate) faster than Anysphere (the developer of Cursor), which reached the milestone in approximately 30 months after launch. In early 2023, the company was bootstrapped to seven figures in ARR with a talent pool of 100K users. By September 2024, Mercor was growing 50% month-over-month and had an annual revenue run rate in the tens of millions.
By February 2025, the company reached $75 million ARR and had helped HR teams evaluate over 468K applicants. Eventually, Mercor achieved $450 million in ARR when it raised its Series C in October 2025. The company generated $6 million in profit in the first half of 2025. As of October 2025, Mercor pays out more than $1.5 million per day, with over 30K contractors earning an average of $85/hour on the platform.
Acquistions
In February 2026, Mercor acquired Sepal AI, a data research company specializing in training data and evaluation benchmarks for frontier AI models. Sepal focused on building RL environments and handling operationally complex human data projects for economically valuable tasks, areas that frontier AI labs have increasingly prioritized. As evidence of this, Anthropic leaders have reportedly discussed spending more than $1 billion on RL environments in 2026. The acquisition could expand Mercor’s capabilities in RL environments and help it take over key relationships that Sepal previously had with frontier AI lab researchers interested in leveraging the technology.
Valuation
In October 2025, Mercor raised a $350 million Series C at a $10 billion valuation, bringing the company’s total funding raised to $483.6 million. Just eight months earlier, Felicis Ventures led the company’s $100 million Series B at a $2 billion valuation. Other investors in Mercor include General Catalyst, Benchmark, Menlo Ventures, and prominent individual investors like Peter Thiel. Following the Series C funding round in October 2025, the three co-founders of Mercor became the world’s youngest self-made billionaires. Foody, Hiremath, and Midha are estimated to each hold 22% of the company.
Key Opportunities
Customer Exodus from Scale AI
A transformative event for Mercor’s trajectory occurred in June 2025, when Meta invested $14.3 billion for a 49% stake in Scale AI. This move prompted AI labs, like OpenAI and Google, to sever ties with Scale over neutrality concerns. Rival post-training data providers, like Mercor, absorbed significant market share from this exodus. As co-founder Hiremath acknowledged:
“It just doesn't happen too often in startups where your biggest competitor gets torpedoed overnight.”
The exodus of frontier lab clients from Scale contributed to Mercor’s revenue trajectory, accelerating from approximately $75 million ARR in February 2025 to $450 million ARR by October 2025. This represented not just temporary revenue growth but the establishment of mission-critical relationships with the world's most sophisticated AI developers at a moment when they were forced to rebuild their supply chains under compressed timelines. Beyond immediate customer capture, it served as a structural opportunity to establish itself as a preferred neutral alternative.
Mercor embedded its platform into the operational workflows of frontier labs precisely as those labs were scaling their post-training budgets aggressively. The data labeling industry was valued at approximately $3.77 billion in 2024 and is projected to reach $17.1 billion by 2030, with a 28.4% CAGR, reflecting the industry-wide shift toward post-training methods as the primary lever for improving model capabilities. Traditional pre-training scaling laws have hit diminishing returns: simply adding more compute and data to base-model training no longer yields proportional capability gains. This forces labs to invest more heavily in RLHF, SFT with expert-generated examples, and evaluation frameworks measuring real-world task performance.
Mercor's early establishment of these customer relationships can also create data advantages that compound over time. Each annotation task generates performance data on expert quality, which annotators produce the highest-agreement labels, which domain specialists excel at specific task categories, and which evaluation rubrics most effectively differentiate model capabilities. This performance data feeds back into Mercor's matching algorithms, enabling increasingly precise expert selection for future projects.
Labs that have run hundreds of annotation projects through Mercor's platform have effectively trained Mercor's systems to understand their specific quality standards and domain requirements, creating a proprietary matching intelligence that competitors cannot easily replicate. The network effects strengthen as the expert pool grows: a larger talent base enables faster project turnaround through parallel work distribution, attracts higher-quality specialists seeking consistent engagement opportunities, and provides redundancy, ensuring quality continuity when individual annotators become unavailable.
Increasing Prioritization of Expert Post-Training Data
In September 2025, OpenAI introduced GDPval, a new evaluation framework that measured model performance across economically valuable, real-world tasks. Since then, frontier AI labs have increasingly reoriented their workflows toward post-training methods requiring domain expert judgment. Models advancing into specialized knowledge work, like legal reasoning, financial analysis, and scientific research, require human feedback from practitioners with years of professional experience. This often cannot be crowdsourced from commodity labeling platforms or those with generalist annotators. Mercor positioned itself early for this structural shift by focusing on high-skill experts, rather than the commodity labeling workforce that characterized Scale AI’s early operations.
The company's APEX benchmark framework, launched in October 2025, also positions Mercor at the forefront of strategic evaluation infrastructure. APEX measures frontier AI model performance on real-world economically valuable tasks across investment banking, management consulting, law, and medicine. Results showed GPT-5 achieving a top score of 64.2%, indicating none of the 21 tested models meet production thresholds for autonomous professional work. This creates a strategic flywheel: APEX benchmarks reveal capability gaps that drive demand for Mercor's expert network to generate the training data addressing those gaps.
The long-term vision extends beyond current AI lab customers into enterprise AI agent deployment across the $40+ trillion knowledge work economy. As companies deploy AI agents for customer service, financial analysis, legal research, and medical triage, they will require rigorous evaluation frameworks to determine which tasks can be automated and how well they are being automated, which still require human expertise.
Key Risks
Worker Misclassification and Litigation
Mercor's business model depends on classifying its experts as independent contractors rather than employees. This classification faces direct legal challenges through active litigation that could fundamentally disrupt operations and unit economics. In October 2025, a class action lawsuit was filed in California by AI trainers and hourly workers accusing Mercor and OpenAI of willfully misclassifying employees as independent contractors, failing to pay overtime, violating California meal break requirements, and failing to reimburse business expenses. They also allege Mercor installed intrusive monitoring software on workers' personal computers without reimbursement, seeking civil penalties of up to $25K per violation.
The regulatory environment is also tightening globally. The EU Platform Workers Directive creates a presumption of employment for platform workers, and Spain fined delivery platform Glovo €79 million for wrongly classifying riders. In the United States, the Department of Labor's stricter economic reality test introduced in 2024 remains in effect for private litigation even as the Trump administration backed off enforcement, and California's AB5 law creates additional classification hurdles for platforms operating in the state where Mercor is headquartered.
If Mercor's workers were reclassified as employees, the company would face obligations for benefits, overtime pay, minimum wage guarantees, payroll tax withholding, and potentially retroactive liabilities that could eliminate the approximately 35% take rate that drives profitability. The lean operational model could become untenable if 30K+ experts convert to W-2 employees requiring benefits administration, HR infrastructure, and compliance overhead.
Customer Concentration and Shifting Data Needs
Mercor's revenue is overwhelmingly concentrated among a small number of frontier AI labs. The company claims to work with all of the top five AI labs and six of the Magnificent Seven technology companies as of December 2025, including publicly disclosed relationships with OpenAI, Anthropic, Meta, and Google. However, this concentration creates structural fragility: if a frontier lab spins up internal training capabilities or builds out its own teams of experts, then Mercor’s core revenue could contract sharply. Additionally, any reduction in spend on post-training human feedback data from even a single client, whether caused by budget constraints or a shift toward synthetic data generation, could have material impacts on Mercor’s top line.
The fundamental long-term threat centers on whether AI models will eventually generate their own training data through synthetic generation or reinforcement learning from verifiable rewards (RLVR), reducing or eliminating demand for human expert feedback. If synthetic data techniques prove sufficient for model improvement across most domains, the entire AI training data market could contract, affecting not only Mercor but also its competitors. The company's $10 billion valuation on approximately $450 million in annualized revenue, representing approximately 22x+ revenue, prices in sustained hypergrowth and successful expansion beyond AI lab customers into broader enterprise markets. Any deceleration in revenue growth, loss of a major customer, adverse litigation outcome, or technological shift toward synthetic data could trigger a significant valuation correction.
Summary
Mercor has executed one of the most remarkable growth trajectories in recent startup history, growing from a college dorm room recruiting platform to over $500 million in annualized revenue and a $10 billion valuation in under three years. Its AI-native vetting infrastructure and performance data flywheel have captured opportunities across frontier AI labs spanning RLHF, STF, rubrics, and RL environments post-training data services. The question of whether synthetic data eventually commoditizes human feedback remains open, as does whether Mercor can justify its valuation as it faces increased competition and the risks of customer concentration. In coming years Mercor will look to define itself across emerging technologies, like RL environments, and expand its AI recruiting marketplace to cement its position as a leader in the post-training data space and further accelerate its growth.




