
Thesis
According to a 2025 survey, 88% of organizations reported using AI “in at least one business function”, up from 78% in 2024, and just 50% in 2022. The growth of enterprise use of generative AI has been even more drastic: from just 33% in 2023 to 79% by 2025. Nevertheless, most enterprises are still in an “experimentation phase” with AI, with almost two-thirds of organizations surveyed in 2025 reporting that they had not yet scaled AI across the enterprise, and only 39% reporting an impact on their profitability.
Scaling AI within enterprises remains a challenge. For most organizations, building a robust AI infrastructure in-house presents significant technical and financial obstacles. Engineering teams must navigate complex scaling challenges, GPU shortages, and integration into existing systems, all while maintaining enterprise-grade security and compliance with data sovereignty laws. These obstacles create a compelling opportunity for infrastructure providers who can abstract away these complexities, allowing businesses to focus on their core AI applications rather than the underlying technical subtleties.
Baseten is a cloud provider that has emerged as a solution to this deployment bottleneck with its inference-first infrastructure platform. Unlike other cloud providers that primarily focus on model training or general-purpose computing, Baseten specializes in the deployment and scaling of production-ready AI models. This entails instant deployment of either open-source library models (e.g., Llama, DeekSeek, Whisper) or the user’s own models. By offering a serverless architecture that spans multiple cloud providers, Baseten gives customers access to scarce GPU resources while delivering up to 40% cost savings compared to in-house solutions. The company's platform enables organizations to transform complex machine learning models into scalable, production-grade applications without the traditional engineering overhead.
Founding Story
Baseten was founded in 2019 in San Francisco, California, by four co-founders: Amir Haghighat (CTO), Tuhin Srivastava (CEO), Pankaj Gupta, and Philip Howes. Prior to building Baseten, Haghighat was an engineering manager at Clover Health, and Gupta was a software engineer at Uber.
Meanwhile, Srivastava and Howes were both co-founders of Shape, an analytics provider for HR data, which was acquired by Reflektive in 2018. Soon after, in 2019, Srivastava started thinking about starting a new company in ML. The crux of his idea: “We just really need to take the whole pipeline cost down, and improve the iteration cycle. Otherwise, most teams are never going to chip.”
Howes and Srivastava grew up together in Australia, and they met Haghihat in 2012 as they were among the first few employees at creator marketplace Gumroad. At the time, Haghigat was head of engineering at Gumroad, while Howes and Srivastava were both machine learning engineers. One of the projects at Gumroad was to train ML models to prevent payment fraud and to moderate user data.
While trying to solve this problem, they realized that they needed full-stack skills to manage the infrastructure to run their algorithms. The founders also realized that as ML training became increasingly accessible, the bottleneck became deploying trained models for inference. As Srivastava stated in May 2025:
“Deploying models. Wrangling Docker. What’s Kubernetes? Integrating data in. Pushing data out. Fighting for resources to build some UI around the model. What we saw was that while many teams had set out to get value from ML, most were ill-equipped from a skills, resources and credibility perspective.”
After extensive conversations with other ML engineers and reflecting on their firsthand experiences, the founding team recognized a shared frustration with managing homegrown ML infrastructure. Consequently, they decided to found Baseten with a mission to provide machine learning infrastructure so that data scientists don’t have to become full-stack engineers in order to build web applications for machine learning models.
This was born of the realization that ML models, even relatively simple ones, often took more than six months to ship under the status quo. The Baseten founders set out to reduce that time to just a few hours. They named the company Baseten after the base-ten blocks used to teach arithmetic. Just as base-ten blocks simplify number systems, Baseten aims to simplify ML.
In 2019, Baseten raised its seed round led by Greylock Partners. Since then, the company has established itself as a provider of AI infrastructure solutions and has grown significantly. The four original founders remained with the company as of February 2026.
Product
Baseten’s core product is a machine learning infrastructure platform optimized for dedicated deployments of various types of AI/ML models. It provides the ability to run mission-critical inference at scale with the Baseten Inference Stack. The platform eliminates the need for developers to manage servers by handling the infrastructure required for high-scale workloads. Baseten supports both proprietary and open-source models.
At the time of Baseten’s formal product launch in 2022, Baseten CEO Srivastava explained the product as follows:
“It’s clear that the performance and capabilities of machine learning models are no longer the limiting factor to widespread machine learning adoption — instead, practitioners are struggling to integrate their models with real-world business processes because of the enormous engineering effort required to do so. With Baseten, we’re reducing this burden and accelerating time to value by productizing the various skills needed to bring models to the real world.”

Source: Product Hunt
Flexible Deployment
Baseten provides infrastructure to run workloads across multiple nodes, cloud servers, and regions. It does not operate proprietary data centers; instead, it uses public cloud providers such as AWS and Google Cloud. With built-in autoscaling, compute costs are minimized by allocating resources based on real-time traffic, ensuring maintenance of customer service-level agreements (SLAs). Baseten ensures 99.99% uptime with cross-cloud capacity management. Cold starts (i.e., the time it takes to provision resources and begin serving traffic on a machine) have been optimized so that new replicas can be spun up within seconds.
There are three deployment options to maximize flexibility:
Self-hosted: Deploy within your own VPC (virtual private cloud). This option is good for meeting in-house, government, and industry standards for data residency compliance. Customers have full data control and can also deploy existing compute capacity, maximizing cost efficiency.
Cloud: Deploy using multi-cloud capacity management (MCM). Baseten offers support for over 10 cloud providers. This provides easy integration with Baseten’s ecosystem and access to state-of-the-art GPUs.
Hybrid: Deploy within your own cloud, with overflow workloads spilling over to Baseten Cloud during traffic spikes. Particularly cost-efficient for companies that possess their own compute resources but experience periods of high traffic. Furthermore, customers can self-host certain workloads for compliance reasons and perform the remainder of the computations on the cloud.
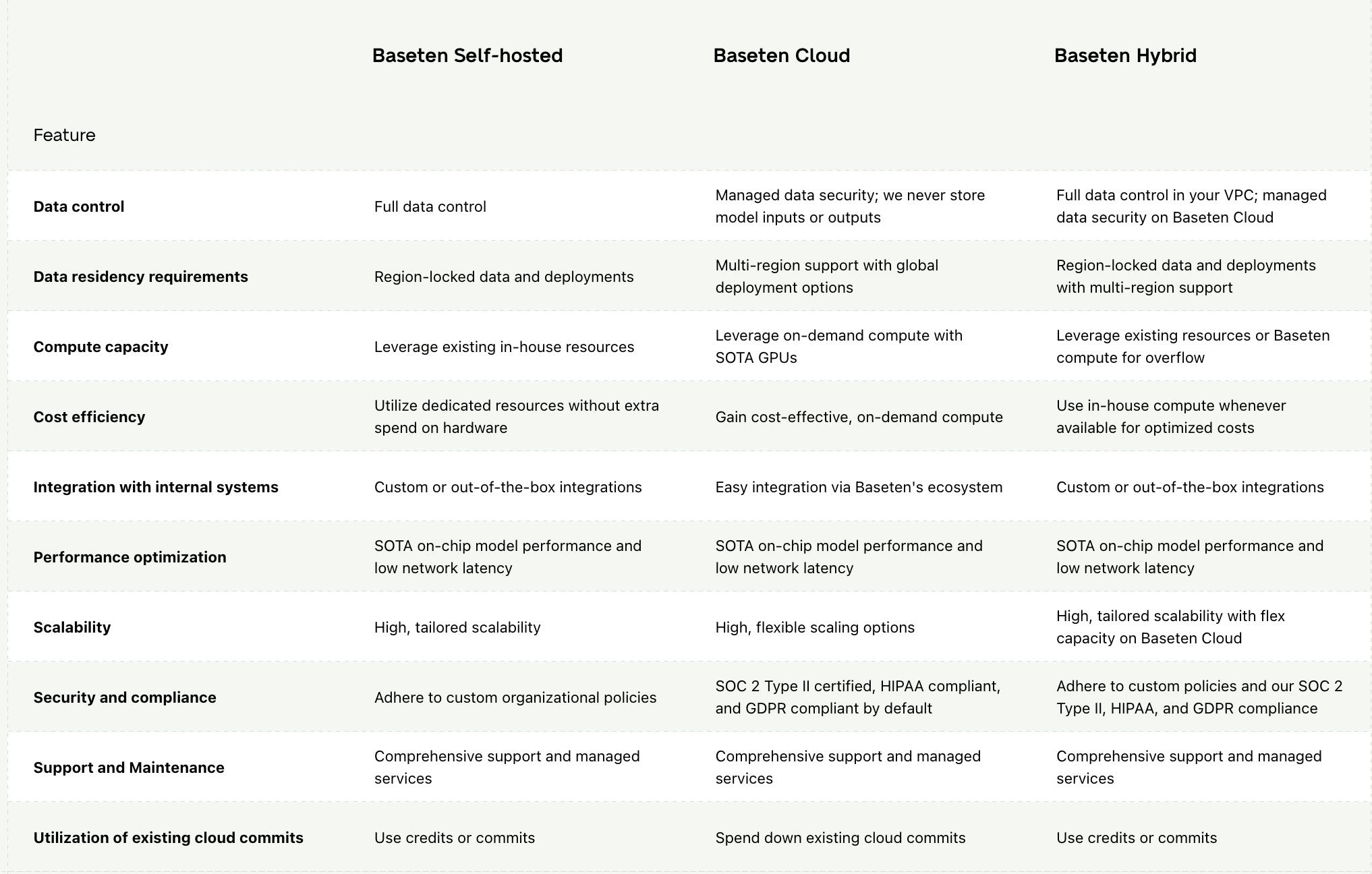
Source: Baseten
Build with Model APIs
Customers who are interested in using open-source models can run pre-optimized frontier models on the Baseten Inference Stack. To ensure data security, Baseten never stores inference inputs or outputs; the platform is also SOC 2 Type II certified and HIPAA compliant. Out-of-the-box models can also be fine-tuned on custom data.
As of February 2026, Baseten supports the following classes of open-source models:
LLMs (e.g., DeepSeek V3.2, GLM 5, MinMx M2.5, Kimi K2.5)
Text-to-Speech Models (e.g., Orpheus 3B WebSockets, MARS8, Orpheus TTS)
Transcription Models (e.g., Whisper Large V3, Ultravox v0.6 70B)
Image Generation Models (e.g., Stable Diffusion XL, Qwen Image, ZenCtrl)
Embedding Models (e.g., EmbeddingGemma, Qwen3 8B Embedding)
It also supports the latest models from notable open-source labs such as DeepSeek, Qwen, and Meta.
Build with Custom Models
Baseten’s Dedicated Deployment product is designed for applications that rely on a custom model that is trained from scratch. Baseten has developed an open-source library, Truss, that enables customers to deploy custom models behind an API endpoint.
Truss containerizes the application’s model, which consists of the following steps:
Packaging the model code and weights into a project that combines inference logic and dependencies.
Configuring the runtime environment to include packages, system dependencies, secrets, etc.
Deploying the model to development mode and continuing to iterate by making live edits.
Promoting the model to prod to handle live traffic.
The development flow on Truss is summarized as follows:
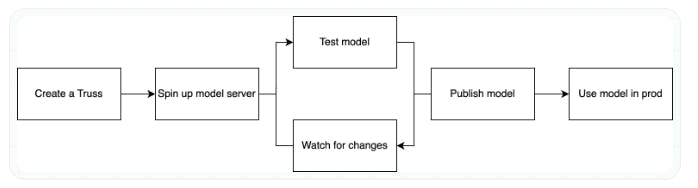
Source: Baseten
Compound AI
Compound AI is designed for building multi-model, multi-step AI pipelines into one consolidated workflow. The concept of “compound AI” was first introduced by Berkeley AI in their paper “The Shift from Models to Compound AI Systems,” which argues that optimal results are more and more often achieved using compound systems with multiple components.
Each component of a Compound AI system can consist of:
An AI/ML model (e.g., speech-to-text, text-to-image)
A processing step (e.g., chunking a file)
Specific architecture (e.g., a rule-based system, a specific ML architecture)
Specific hardware (e.g., CPU, GPU)
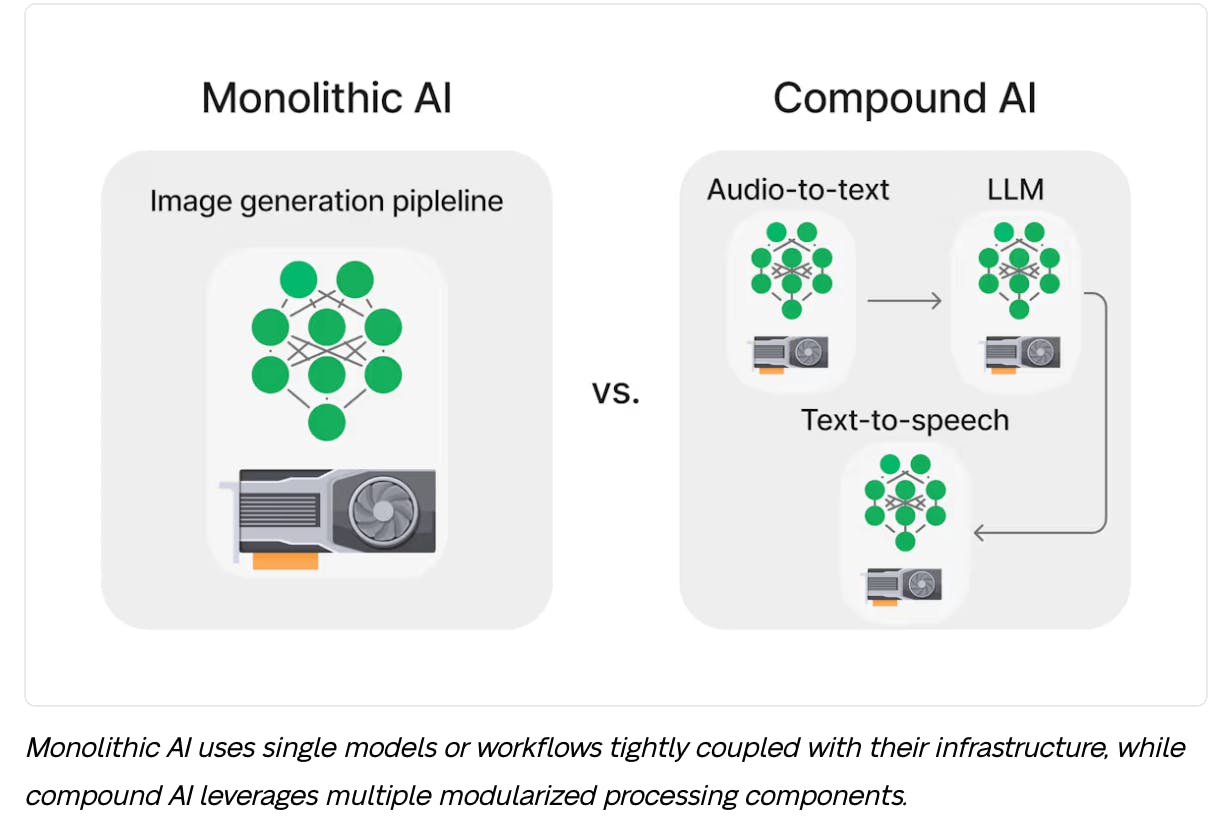
Source: Baseten
Compound systems take “experts” for specific tasks and chains them together, maximizing overall performance. Performance gains become even more obvious once resource usage is improved by allocating the optimized hardware for every step. For instance, we can design a modularized system that utilizes CPUs for speech-to-text and GPUs for transcriptions, thereby preventing CPU-bound operations from blocking GPUs.
Compound AI can perform more complicated tasks than monolithic models, providing both flexibility and adaptability. Additionally, it is easier for devs to iterate on a modular workflow; individual parts can be improved or swapped for better alternatives without affecting the rest of the system. Modularizing workflows also opens opportunities to reuse components in different pipelines, providing comparable benefits to modularizing a codebase.
Cost efficiency is another added benefit. While training one massive LLM, a smaller fine-tuned LLM chained with a search heuristic function may be significantly cheaper. Furthermore, individual models or tools can be replaced with cost-effective alternatives when they become available on the market. Task-specific hardware also cuts down costs, while parallelization across nodes can improve GPU utilization.
Baseten has simplified data flow between steps, minimized latency, and optimized hardware/software for scaling with Compound AI. Chains is the Python SDK and framework for building compound systems. A Chain is composed of “chainlets,” which are modular services that can be linked for inference.
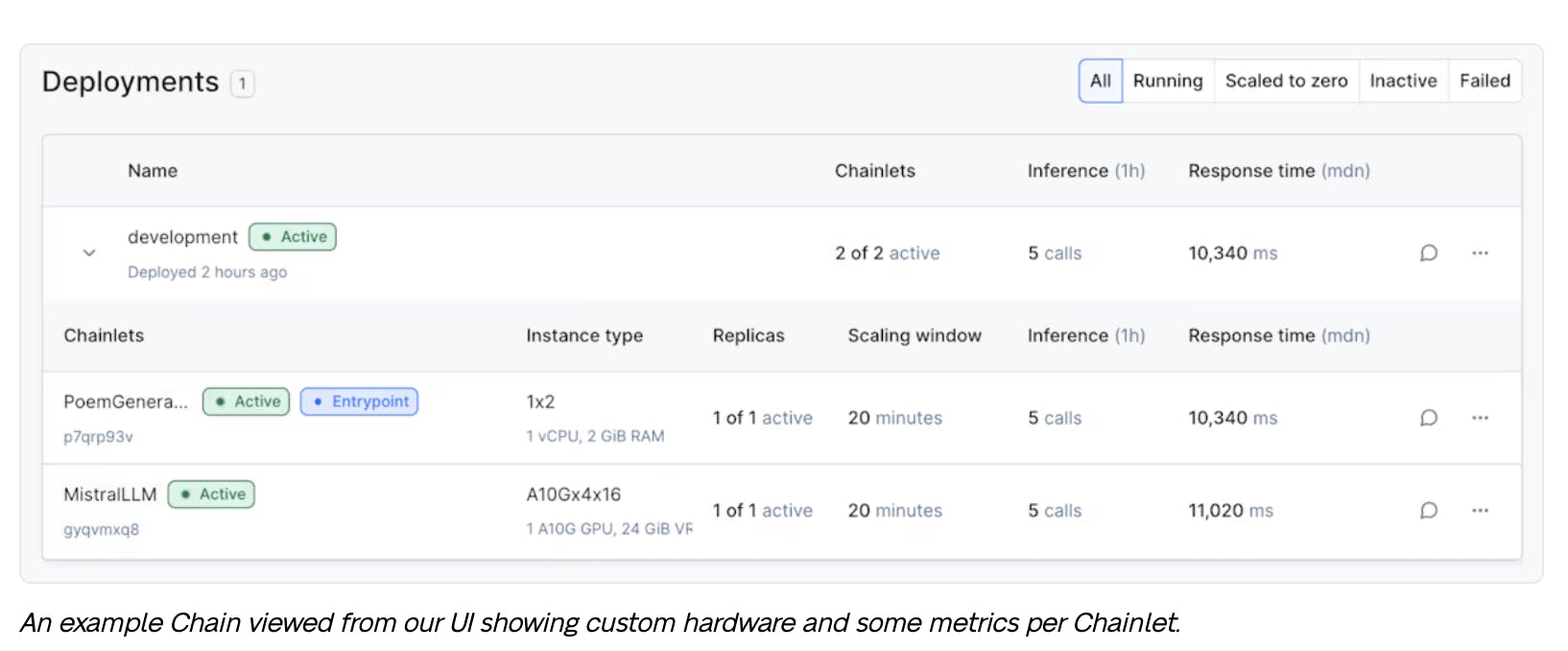
Source: Baseten
Baseten Training
Although Baseten’s core focus is inference, it also provides training infrastructure that is built to support training jobs of any size and models of any modality. The company offers access to state-of-the-art hardware, ranging from B200s to T4s. One feature is that checkpoints can be tracked during training and shipped to production. Another key feature is that the platform has no size limits for datasets. Baseten supports integrations with Weights & Biases, Hugging Face, and Amazon S3. Debugging tools for everything from GPU memory to code inefficiencies to hardware metrics are provided to streamline the training process.
Market
Customer
Baseten customers include AI-native startups and high-growth technical teams that need to deploy and scale machine learning models in production without managing complex GPU infrastructure. Its platform is designed for ML engineers and data scientists who prioritize high-performance serving, reliability, and security for mission-critical generative AI applications.
Baseten provides its services to customers wishing to deploy proprietary models into production. With the rise of LLMs and other frontier models, Baseten began supporting the deployment of model APIs in May 2025, expanding its customer base to include those seeking out-of-the-box models. In May 2025, Baseten simultaneously launched its model training infrastructure, signaling a shift toward capturing customers beyond the inference market.
One notable customer is Patreon, a monetization platform that supports over 250K creators as of January 2025. Patron utilizes Baseten to deploy OpenAI’s Whisper for transcribing creator content to provide auto-generated closed captions. Annually, this saves Patreon over 440 engineer hours, $600K, and 70% in GPU costs.
As of February 2026, other notable customers of Baseten included high-profile startups such as Superhuman, World Labs, Abridge, Clay, Cursor, Decagon, Hex, HeyGen, Mercor, Notion, Wispr, Quora, Writer, and Retool. These companies represent a wide range of industries, ranging from generative AI to developer tooling.
Market Size
The shift from training to inference has arrived: as Nvidia CEO Jensen Huang commented in 2024, AI has transitioned from training into production. This creates a substantial growth opportunity for ML infrastructure.
Nvidia, which supplied 92% of the world’s GPUs as of Q1 2025, has seen significant demand for running inference on its hardware. Between June 2023 and June 2024, 40% of Nvidia’s data center revenue was driven by inference. By 2028, Nvidia’s inference spend is projected to range from $450 billion to $900 billion. By 2030, 60-70% of AI workloads are projected to shift to real-time inference.
As a result, the AI inference infrastructure market is expected to continue growing to meet increasing demand. Globally, the AI inference market was valued at $106.2 billion in 2025, and is expected to grow to $255 billion by 2030, representing a 19.2% CAGR.
Competition
Large Cloud Providers
Google Cloud Platform (GCP)
GCP’s core inference service is offered as part of its Vertex AI platform. Some key features include autoscaling model endpoints and providing ready-to-deploy foundation models. Vertex AI offers quick access to Google’s multimodal Gemini models and text-to-video Veo models. Third-party models are also available, including Anthropic’s Claude and Meta’s Llama. Vertex AI also provides access to optimized AI/ML hardware, including its proprietary Tensor Processing Units (TPUs), which are optimized for speed and cost in training and inference.
Amazon Web Services (AWS)
Amazon SageMaker Inference is an AWS service for deploying ML models with low latency and high throughput. Some features include serverless inference, shadow testing, intelligent routing, autoscaling for elasticity, asynchronous inference, and offline inference on data batches. SageMaker supports prebuilt Docker images for common frameworks such as TensorFlow and PyTorch, or users can build their own container. Customers span across many industries, with examples including Figma, Perplexity, Vanguard, Salesforce, Intuit, AstraZeneca, and AT&T.
Microsoft Azure
Microsoft provides two separate products for ML inference:
Azure Machine Learning: This library enables real-time inference via endpoints, which are stable URLs used to request or invoke a model. The Azure ML inference router is deployed on Kubernetes to manage auto-scaling and load balancing.
Azure OpenAI: This service provides REST API access to OpenAI’s models. Unlike using OpenAI’s API directly, users receive all the security benefits of Azure, such as private networking, regional availability, and responsible AI content filtering.
Microsoft holds exclusive cloud-hosting rights to GPT models, giving Azure a competitive edge over other inference providers. It is speculated that Microsoft’s OpenAI integration creates a network effect that locks customers into using Azure.
MLOps Infrastructure Providers
Together AI
Together AI was founded in 2022. The company has raised $533.5 million in total funding across four rounds as of February 2026. The company raised $305 million in Series B funding in February 2025, valuing the company at $3.3 billion. Together AI offers some unique features that are unavailable on Baseten, such as Mixture-of-Agents, a technique that uses “a layered architecture where each layer comprises several LLM agents.” Its platform supports over 200 open-source models across various modalities and serves more than 450K AI developers.
Lambda
Lambda (formerly Lambda Labs) was founded in 2012 and provides cloud infrastructure services specialized for AI and machine learning workloads. It focuses on both training and inference, as opposed to Baseten, which focuses primarily on the latter. The company has raised $3.2 billion in total funding as of February 2026, including a $1.5 billion Series E in November 2025.
Fireworks AI
Founded in 2022, Fireworks AI provides a platform for deploying and optimizing model APIs with a focus on fast, cost-effective inference. It has raised a total of $327 million in funding as of February 2026, including a $250 million Series C at a $4 billion valuation in October 2025. The company processed 10 trillion tokens per day as of October 2025 and claims to offer up to 40x faster performance and 8x lower inference costs than competitors. The company also has 10K companies among its customers, a 10x increase from its 2024 Series B. Fireworks specifically optimizes for model APIs rather than also focusing on custom model deployment.
Modal
Founded in 2021, Modal provides a cloud-based infrastructure platform that allows developers to run code in the cloud without having to configure or set up infrastructure. The company has raised a total of $110 million in funding as of February 2026, including a $87 million Series B in September 2025 that valued the company at $1.1 billion. Modal Labs is a major competitor in the inference space for Baseten. Modal's differentiator is its developer-centric approach, focusing on making infrastructure invisible through Python decorators that automatically handle containerization and scaling.
Replicate
Founded in 2019, Replicate provides a platform for running machine learning models in the cloud. Replicate specializes in having an API-first approach and has models that range from video generation to object detection. The company raised $40 million in Series B funding in December 2023, reaching a valuation of $350 million, with backing from a16z. As of February 2026, Replicate has raised $57.8 million in total funding. Unlike Baseten's enterprise focus, Replicate targets individual developers and small teams with a focus on ease of use and pre-configured open-source models.
Baseten’s Positioning
Baseten seeks to differentiate itself through its focus on inference, which has resulted in hyper-optimizations that save customers on inference costs. It also seeks to position itself as a reliable and secure option. According to Baseten CEO Srivastava:
“In this market, your No. 1 differentiation is how fast you can move. That is the core benefit for our customers…You can go to production without worrying about reliability, security and performance.”
On the other hand, cloud giants provide a plethora of compute and infrastructure services and are generalists rather than specialists. In contrast, Baseten does not own cloud resources, avoiding vendor lock-in. Users can move between different cloud environments, self-host, or use a hybrid model. These three hosting options are a unique feature of Baseten. Baseten also claims to be more affordable than using model APIs directly; Srivastava states that “There are a lot of people paying millions of dollars per quarter to OpenAI and Anthropic that are thinking, ‘How can I save money?’ And they’ve flocked [to us].”
Compared to other MLOps infrastructure companies, Baseten has strong support for both custom models and model APIs, with model APIs being newly introduced in May 2025. While many competitors focus on selling to smaller startups and individual devs, Baseten’s advanced features, such as Compound AI, also make it well-suited for larger enterprises.
Business Model
Baseten offers several pricing options, all of which support deploying custom, fine-tuned, and open-source models. It has three tiers of pricing:
Basic: $0, pay-as-you-go. Designed for testing and small-scale usage.
Pro: Priced with volume discounts. Provides priority access to GPUs, dedicated compute, and higher API rate limits.
Enterprise: Custom pricing for large deployments. Includes custom SLAs, model training, self-host or hybrid deployment plans, full data residency control, and security/compliance.
For running model APIs on the Baseten Inference Stack, users are charged based on the number of generated tokens:
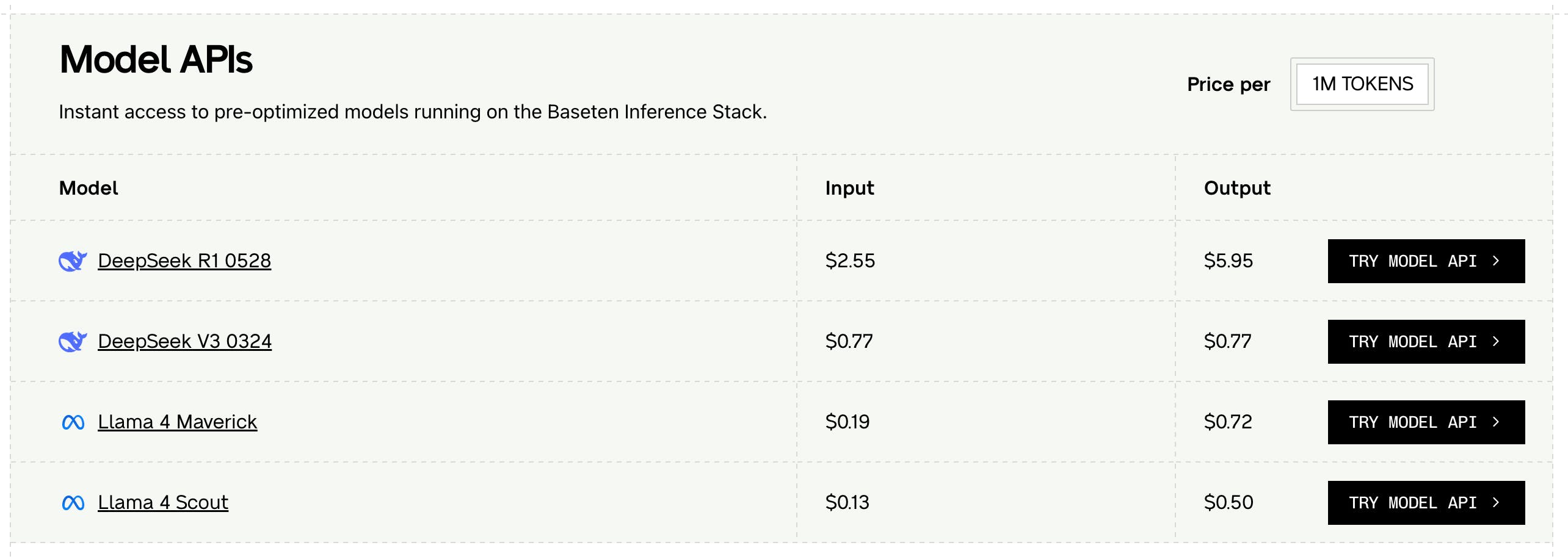
Source: Baseten
For running inference on dedicated deployments, the pricing is dependent on the type of GPU/CPU instance and the number of minutes spent computing:
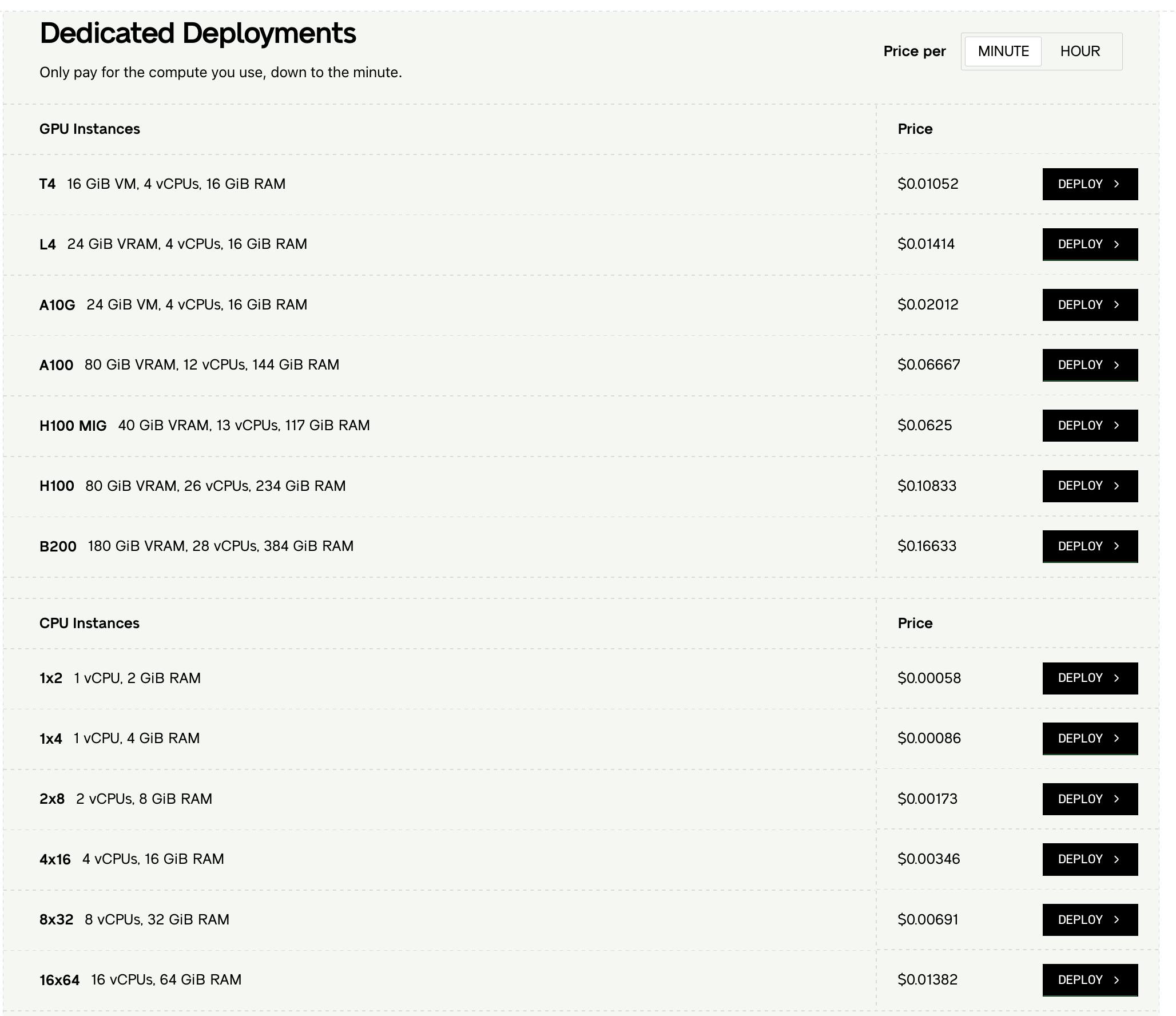
Source: Baseten
As with the dedicated deployments pricing system, model training pricing depends on instance type and compute minutes. GPU instance costs are identical between training and inference. A special feature of Baseten training is that 20% of the training cost is credited to users for use on inference.
Baseten offers free credits to new accounts for both dedicated deployments and model APIs. For Pro and Enterprise plans, compute discounts can be negotiated. Baseten partners with major cloud providers, including Google Cloud and AWS, paying these providers to host its servers.
Traction
Through the end of 2022, the company generated "basically zero" revenue despite being founded in 2019. Baseten saw a transformation in its trajectory after pivoting to focus on inference in 2023. Following this, Baseten’s revenue grew to $2.7 million in 2023. Revenue continued its strong growth, increasing sixfold in fiscal year 2024, driven by increased adoption of generative AI models.
As of March 2024, Baseten served about 20 large enterprises and tens of thousands of developers. By February 2025, it served over 100 large organizations and hundreds of smaller businesses. The 5x increase in large enterprise customers over just 11 months marks a substantial pace of customer acquisition.
Baseten's investors have commented on its traction, with Spark Capital's Will Reed noting the company was winning a disproportionate share of customers despite not being the cheapest option. In January 2026, the company disclosed that it had grown inference volume 100x over the preceding year.
In December 2025, Baseten announced the acquisition of Parsed, a reinforcement learning startup focused on post-training and continual learning, as part of a strategy to expand from inference infrastructure into a more vertically integrated platform spanning training, evaluation, and deployment. The same month, the company also signed a strategic collaboration agreement with AWS. Commenting on the agreement, CEO Tuhin Srivastava stated:
“Through this collaboration, customers can combine Baseten’s inference stack with the AWS secure global infrastructure to run their most demanding AI workloads while maintaining full control of their data and leveraging their existing AWS investments.”
Valuation
In January 2026, Baseten raised a $300 million Series E at a $5 billion valuation, doubling its valuation in only four months after having raised a a $150 million Series D at a ~$2.2 billion valuation. The Series E was co-led by IVP and CapitalG, Alphabet’s growth investing arm. Other investors in the round included 01A, Altimeter, Battery Ventures, BOND, BoxGroup, Blackbird Ventures, Conviction, Greylock, and Nvidia. The round brought the company’s total funding to $585 million.
The company has experienced rapid growth in funding and valuation over the past few years. In April 2022, the company announced it had raised its Series A, but few details were disclosed beyond that its seed (raised in 2019) and Series A totalled $20 million in funding. The Series A was led by Greylock’s Sarah Guo, who also co-led the seed.
Then, almost two years later, in March 2024, Baseten raised $40 million in Series B funding, which was led by IVP and Spark Capital. Existing investors, including Greylock, South Park Commons, Lachy Groom, and Base Case, also participated. This round valued the company at more than $200 million.
In February 2025, less than a year later, the company raised a $75 million in Series C funding, co-led by IVP and Spark Capital. Existing Series B investors participated, as did new investors Adam Bain and Dick Costolo of 01a. This round valued Baseten at $825 million, more than 4x its valuation from the previous round.
Key Opportunities
AI Boom
Generative AI has emerged as a standout trend in market growth since 2022, with a rapid uptick in investment in the space. In 2024, $109.1 billion was invested in private AI companies in the U.S. alone, up 19.7% from 2023. This trend has catalyzed growth in the AI infrastructure market, which is projected to increase from $135.8 billion in 2024 to $394.5 billion by 2030, at a 19.4% CAGR. In 2025, major tech companies were committing over $300 billion to AI infrastructure. This presents a significant market opportunity for Baseten, particularly as companies can shift from experimentation (training) to production-grade products (inference). Baseten is well-equipped to serve this transition, meeting the growing demand for tools that accelerate time-to-value for AI investments.
Multi-Cloud Adoption
A growing number of enterprises are shifting to multi-cloud infrastructure. In 2024, 70% of firms used two or more cloud providers. By the end of 2025, over 85% of organizations were expected to use hybrid or multi-cloud strategies, citing reasons including avoiding vendor lock-in and optimizing for cost, performance, and resilience. This provides Baseten with an edge over cloud giants such as AWS. More than 94% of organizations with more than 1K employees have a significant portion of their workloads in the cloud. This is significant because larger organizations can generate higher revenue for B2B SaaS companies like Baseten.
Regulation Environment
Due to the security risks posed by AI, governments around the globe have begun tightening restrictions concerning AI applications. For example, in 2024, the EU passed the General Data Protection Regulation to protect data privacy. These stricter data protection laws may work in Baseten's favor. Rather than spending valuable developer hours on regulatory compliance, companies may find it faster and more cost-effective to use Baseten for its built-in security features.
High Customer Retention
Once engineers set up their models on Baseten, it will likely require significant engineering effort to switch to a different inference platform or build proprietary infrastructure. This technical lock-in naturally encourages continued usage of the platform. As long as Baseten’s customers continue to generate traffic, Baseten can operate on a recurring revenue model. Its pricing system provides financial predictability and incentivizes long-term customer engagement. Baseten reported near-zero churn as of February 2025.
Key Risks
GPU Supply Chain
Despite multi-cloud sourcing, securing NVIDIA H100 clusters remains challenging for all AI infrastructure companies, Baseten included. Global GPU demand outpaces supply, with major companies like OpenAI and Amazon experiencing shortages in 2025. Baseten’s business model relies on securing GPU contracts with large providers, which is not guaranteed when resources are scarce.
Competitor Price Undercutting
A critical threat to Baseten’s business model is price undercutting on inference workloads by platforms such as AWS and Microsoft Azure. Baseten competes directly with cloud giants such as AWS SageMaker, Google Cloud Vertex AI, and Azure ML Studio, which offer a wide range of integrated ML inference tools. These providers have far greater resources, more mature ecosystems, and built-in customer bases. They have the upper hand for several reasons, including owning their own cloud servers and benefiting from economies of scale. These factors make it easier to outprice smaller startups such as Baseten. AWS, for instance, charges $3.933 per hour for an H100 instance, whereas Baseten charges $6.499 for the same GPU.
Closed-Source Model APIs
Many popular, state-of-the-art models are built by AI research firms that offer access only through proprietary model APIs. For example, OpenAI’s GPT and Anthropic’s Claude are closed source and therefore not available on Baseten. OpenAI alone accounts for an estimated 80% of US generative AI tool traffic. Anthropic has gained traction, with revenue surpassing $4 billion in July 2025. Since OpenAI and Anthropic offer proprietary model APIs, Baseten faces a significant threat if consumers seek stronger closed-source models. If companies choose to run inference on models that are neither open-source nor custom-trained, this may jeopardize Baseten’s market position.
Summary
Through its inference-optimized platform, Baseten has successfully established itself as a critical enabler of production-grade AI. With partnerships with leading AI startups, the company is well-positioned to capitalize on the growing AI infrastructure market. On one hand, several challenges lie ahead. Maintaining cost competitiveness against cloud giants and navigating GPU supply constraints will be pivotal to further growth. On the other hand, the AI boom, the multi-cloud paradigm, the tightening regulatory environment, and Baseten’s high retention rate provide strong signals for growth. As Baseten CEO Tuhin Srivastava expresses: "Running inference at scale is both the hardest and most critical challenge for turning AI into a product."


